

1

產業
當成本不再是負擔,大數據將實現哪些可能?
人們每天上傳至雲端的檔案數量,多達一億張相片、十億份文件… 更別提數位影音、交易、生物醫療… 每天全球所創造的資料量高達2.5艾位元組(exabyes, 即1000,000,000,000,000,000)。
但資料量大就是大數據嗎? 究竟什麼是大數據? 又為何大數據會在近幾年突然興盛起來? 時常耳聞的Hadoop, MapReduce, Spark 技術又是什麼呢?
今天,就讓我們來聊聊什麼是大數據(Big Data)。
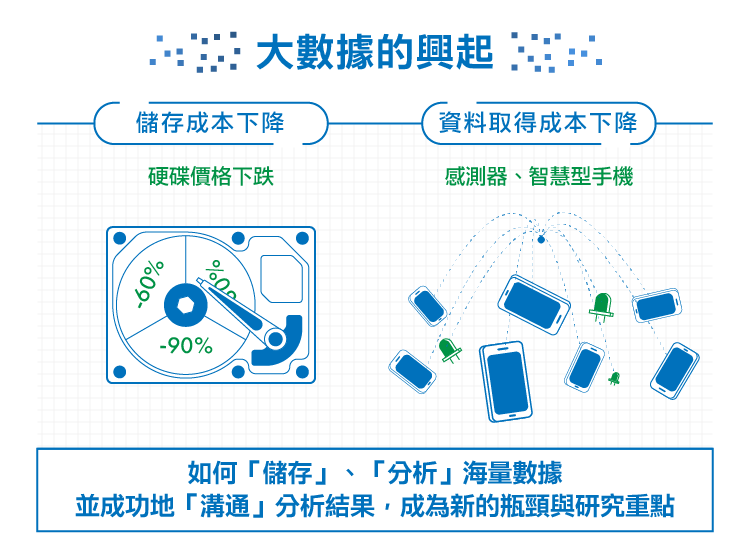
「儲存成本」與「資料取得成本」因科技進步而大幅下降,造就了這個年代大數據的興起。
30年前,1TB檔案存儲的成本為16億美金,如今一個1TB的硬碟不到100美金。同時間,全球各行業的資料量成長更是急速攀升;根據預估,從2013年至2020年間將成長10倍的資料量,資料總量將從4.4ZB增加至44ZB。
以天文學為例,2000年美國太空總署在新墨西哥州發起的史隆數位化巡天 (Sloan Digital Sky Survey)專案啟動時,望遠鏡在短短幾周內收集到的資料,已經比天文學歷史上總共收集的資料還要多。
在生物醫學領域,新型的基因儀三天內即可測序1.8 TB的量,使的以往傳統定序方法需花10年的工作,現在1天即可完成。在金融領域,以銀行卡、股票、外匯等金融業務為例,該類業務的交易峰值每秒可達萬筆之上。
Google每天要處理超過24 千兆位元組的資料,這意味著其每天的資料處理量是美國國家圖書館所有紙質出版物所含資料量的上千倍。 Facebook每天處理500億張的上傳相片 ,每天人們在網站上點擊”讚”(Like)按鈕、或留言次數大約有數十億次。
YouTube的使用者人數已突破十億人,幾乎是全體網際網路使用者人數的三分之一,而全球的使用者每天在YouTube 上觀看影片的總時數達上億小時。在Twitter上,每秒鐘平均有6000多條推文發布,每天平均約五億條推文。
千禧年開始,天文學、海洋學、生物工程、電腦科學,到智慧型手機的流行,科學家發現:仰賴於科技的進步(感測器、智慧型手機),資料的取得成本相比過去開始大幅地下降──過去十多年蒐集的資料,今朝一夕之間即能達成。
也因為取得數據不再是科學研究最大的困難,如何「儲存」、「挖掘」海量數據,並成功地「溝通」分析結果,成為新的瓶頸與研究重點。
接下來,我們將進一步介紹大數據的定義、特性,與發展重點。
大數據意指資料的規模巨大,以致無法透過傳統的方式在一定時間內進行儲存、運算與分析。至於「大」是多大,則各家定義不一,有兆位元組(TB)、千兆位元組(PB)、百萬兆位元組(EB)、甚至更大的規模單位;然而,若真要找到符合這麼大規模數據量的企業倒也是不容易。
事實上,根據451 Research 的資料科學家 Matt Aslett,他將大數據定義為「以前因為科技所限而忽略的資料」,討論這些以前無法儲存、分析的資料。如本文第一段所言,由於在近年來儲存成本降低與資料獲取量變大,因而能觀察到不曾注意過的商業趨勢,讓企業做出更全面的考量。
無論企業規模大小,我們應注重的不僅是數據量本身,而應將「大數據」作為在科學研究與商業方法的運營心態:大數據需要全新的處理方式,以新型的儲存運算方法分析數據、產出溝通圖表,並將該分析結果視為一種戰略資產。
目前大部份的機構將大數據的特性歸類為「3V」,包括資料量 (Volume)、資料類型 (Variety)與資料傳輸速度 (Velocity)。
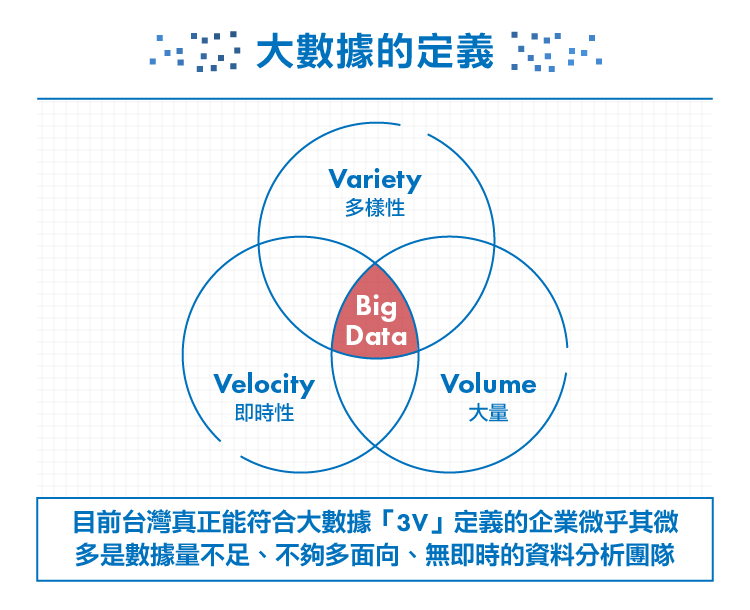
無論是天文學、生物醫療、金融、聯網物間連線、社群互動…每分每秒都正在生成龐大的數據量,如同上述所說的TB、PB、EB規模單位。
舉一個簡單的例子:
│資料類型│ 0 │ 0 │ 1 │ 0 │ 0 │ 1 │ 0 │ 0 │ 1 │ 0 │ 0 │ 1 │…
就算上述資料量高達 1 TB,採用傳統統計方法仍能很容易地找到資料規律。也因此,真正困難的問題在於分析多樣化的資料──從文字、位置、語音、影像、圖片、交易數據、類比訊號… 等結構化與非結構化包羅萬象的資料,彼此間能進行交互分析、尋找數據間的關聯性。
大數據亦強調資料的時效性。隨著使用者每秒都在產生大量的數據回饋,過去三五年的資料已毫無用處── 一旦資料串流到運算伺服器,企業便須立即進行分析、即時得到結果並立即做出反應修正,才能發揮資料的最大價值。
目前台灣真正能符合大數據「3V」定義的企業微乎其微,在數據分析上更是不可能──通常是由資料科學團隊向企業的IT部門登入企業伺服器取得資料,除了量與多樣性已難以達到以外,在「即時性」這一點上便不符合;唯有企業內部自建即時的資料分析團隊並隨時產出分析反饋,方能稱作大數據分析。
我們在上述提到了如何用非傳統的方法「儲存」、「挖掘」與「溝通」資料以挖掘嶄新商業機會,是當前的一大技術方向。
講到大數據,我們便不能不提與之息息相關的軟體技術──「Hadoop」。
Hadoop 由Java語言撰寫,是Apache軟體基金會發展的開源軟體框架。不但免費、擴充性高、部屬快速,同時還能自動分散系統負荷,在大數據實作技術上非常受歡迎。
Hadoop的核心主要由兩個部分所構成,一為資料儲存:「Hadoop分散式檔案系統(Hadoop Distributed File System)」;二為資料處理:「Hadoop MapReduce」。
– Hadoop分散式檔案系統 (Hadoop Distributed File System, HDFS):
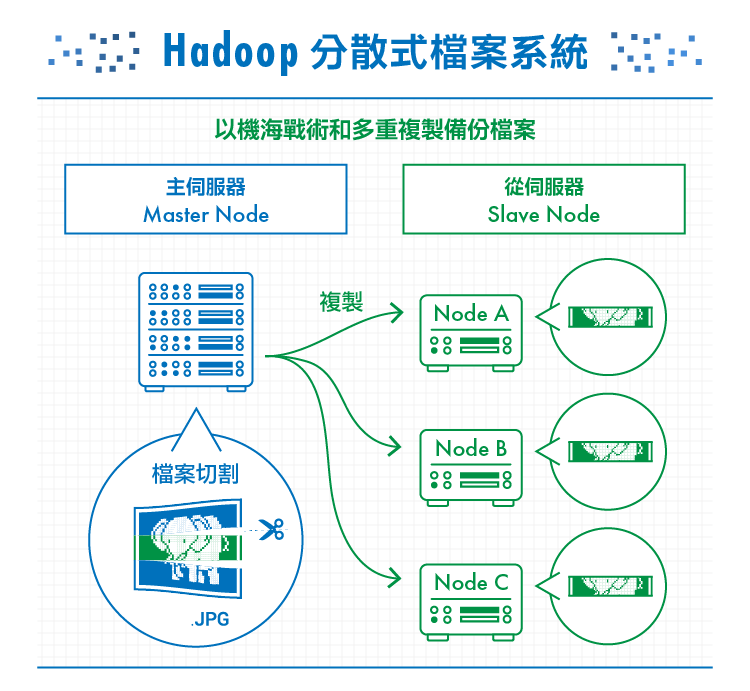
由多達數百萬個叢集(Cluster)所組成,每個叢集有近數千台用來儲存資料的伺服器,被稱為「節點」(Node)。其中包括主伺服器(Master Node)與從伺服器(Slave Node)。
每一份大型檔案儲存進來時,都會被切割成一個個的資料塊 (Block),並同時將每個資料塊複製成多份、放在從伺服器上保管。當某台伺服器出問題時、導致資料塊遺失或遭破壞時,主伺服器就會在其他從伺服器上尋找副本複製一個新的版本,維持每一個資料塊都備有好幾份的狀態。
簡單來說, Hadoop 預設的想法是所有的Node 都有機會壞掉,所以會用大量備份的方式預防資料發生問題。另一方面,儲存在該系統上的資料雖然相當龐大、又被分散到數個不同的伺服器,但透過特殊技術,當檔案被讀取時,看起來仍會是連續的資料,使用者不會察覺資料是零碎的被切割儲存起來。
– Hadoop MapReduce:
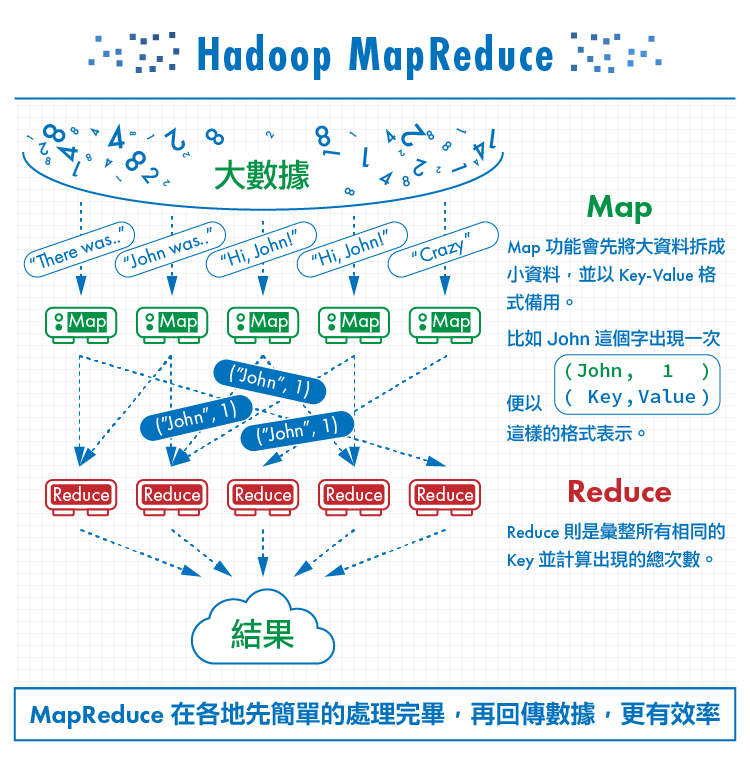
MapReduce是一種計算模型,分為Map和Reduce兩項功能。
「Map」功能會先將大資料拆成小資料,並以Key-Value格式備用。比如有數千萬份的資料傳入,Map會計算每個字出現的次數;比如computer這個字出現了一次、便以(computer, 1)這樣的 (Key, Value) 格式表示。
「Reduce」則是彙整,意即彙整所有相同的Key並計算出現的總次數。
簡單來說,Map僅是在各節點上計算少量數據,而Reduce則是統計各地數據、將結果送回主伺服器進行公布。MapReduce的好處在於無須將所有資料都搬回中央去運算,而能在各地先簡單的處理完畢後、再回傳數據,如此更有效率。
總而言之,Hadoop分散式檔案儲存系統(HDFS)是一個超大型的儲存空間,並透過Hadoop MapReduce進行運算。
Hadoop成功解決了檔案存放、檔案備份、資料處理等問題,因而應用廣泛,成為大數據的主流技術。Amazon、Facebook、IBM和Yahoo皆採取Hadoop作為大數據的環境。
事實上近兩三年來,Apache軟體基金會另一個新星「Spark」隱隱有取代Hadoop MapReduce的態勢。
在大規模資料的計算、分析上,排序作業的處理時間,一直是個重要的指標。相較於Hadoop MapReduce在做運算時需要將中間產生的數據存在硬碟中,因此會有讀寫資料的延遲問題;Spark使用了記憶體內運算技術,能在資料尚未寫入硬碟時即在記憶體內分析運算,速度比Hadoop MapReduce可以快到100倍。

許多人誤以為Spark將取代Hadoop。然而,Spark沒有分散式檔案管理功能,因而必須依賴Hadoop的HDFS作為解決方案。作為與Hadoop 相容而且執行速度更快的開源軟體,來勢洶洶的Spark想取代的其實是Hadoop MapReduce。
另一方面,Spark 提供了豐富而且易用的API,更適合讓開發者在實作機器學習演算法。2015年6月,IBM宣佈加入Apache Spark社群,以及多項與Spark專案相關的計畫,IBM將此次的大動作宣稱為:「可能是未來10年最重要的開放源碼新計畫」,計畫培育超過一百萬名資料科學家。
介紹完了Hadoop基礎架構後,讓我們來看看資料分析上的最熱門技術──「機器學習」。
如何從大數據中挖掘資料規律,以改善科學或商業決策,以手動方式探索資料集的傳統統計分析,已難以應付大數據的量與種類。唯有透過「機器學習」,以電腦演算法達成比以往更深入的分析。
機器學習發端於1980年代,是人工智慧的一項分支。透過演算法模型建構,使電腦能從大量的歷史數據中學習規律,從而能識別資料、或預測未來規律。
從Google搜尋技術與廣告,到醫療、金融、工業、零售、基礎建設… 機器學習的應用涵蓋各行各業,一夕之間即可能有著天翻地覆的革新。
後續的系列文章中,我們將帶領讀者進一步瞭解機器學習的發展潛能。
隨著「數據導向決策」的時代來臨,資料科學家在分析完數據後,如何成功地將分析結果傳遞出去、使企業接收到該資訊呢? 資料視覺化 (Data Visualization)的重要性與潛在的龐大商機因此愈發被凸顯出來。
人類的大腦在閱讀圖像畫面的速度遠比文字更快。資訊視覺化的優勢在於──以一目瞭然的方式呈現資料分析結果,比查閱試算數據或書面報告更有效率。
「Tableau軟體」和微軟(Microsoft, MSFT-US)開發的「Power BI」產品皆主打在資料分析後,將自動產生簡潔易懂的資訊圖表,並隨著新增的數據分析結果生成儀錶板(Dashboard),供使用者查詢動態報表、指標管理等服務。
我們在本篇文章中介紹了大數據的精神意義──大數據無統一定義,代表著傳統的儲存、分析技術難以應付的高維度資料。實際上大數據的特性包括了3V:量(Volume)、多樣性(Variety)與即時性(Velocity)。
我們也介紹了大數據在「儲存」、「挖掘」與「溝通」的重點發展方向,從Hadoop、機器學習與資料視覺化,大數據的相關技術日新月異。唯有建立合適的資料科學團隊、將數據視為企業的策略性資產,方能發掘無所不在的商業機會,在此波數據浪潮下創造競爭優勢。
【延伸閱讀】
超好賺!
每天都有任務能拿獎勵,快點擊查看!
















全球CMOS影像感測器的領導廠商.png)
