

1
商品期貨基本面分析:供需平衡表_-.png)
投資
在過去的 25 年中,每年的第一週都是我用金融數據來玩「魔球」(Moneyball,原意為採用數據分析手段來代替常規的球探經驗來輔助決策) 的時間。我在那一個星期裡會搜集世界上所有上市公司的財務數據,想看看我能從這些數據裡學到什麼,以便在這一年派上用場。我會把研究報告上傳到自己的網站上,並且按照國家和產業分類,方便大家參考。
我會在這個月接下來的時間裡陸續發表一些文章,來總結一下我在去年的數據裡都學到了什麼。總結來說,這個系列不僅會提供大家一些不同的觀點和注意事項,還會強調在數據方面有什麼值得注意的地方。
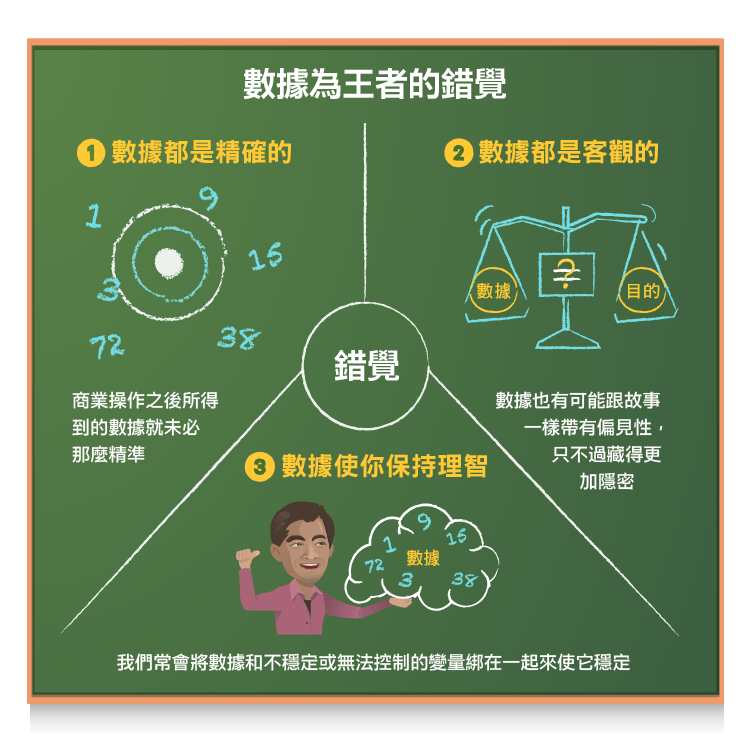
在我之前一篇講邏輯和數據的文章裡,我承認自己比起說故事,實際上更像是以數據為王的人,也坦承完全依賴數據確實會在估值和投資上犯錯。實際上,如果你讀了我在今年初發表的那篇關於數據的文章,你就會發現,我其實是數據至上的人,而且也受數據的三個錯覺影響:
1. 數據都是精確的:事實上,數據只有在運算過程正確的時候才可靠,在商業上所得到的數據就沒那麼精準了。
因此,你要是想看我評估上傳的公司其資本報酬率 (ROC) 或者資金成本之類的數據,那麼請注意:前者是屬於會計數據,也就是在花費和折舊方面的變動都會帶給 ROC 巨大的變化;後者是市場數據,不僅會隨時發生變化 (主要是因為稅率和風險溢價) ,在我做評估時也會選擇調整風險溢價和風險參數時的誤差。
2. 數據都是客觀的:這是數據至上的人對愛說故事的人的抱怨,愛說故事的人總是異想天開的把自己的偏見帶入到他們想講的故事裡,從而影響了訂價和投資。但問題是,數據也有可能跟故事一樣帶有偏見,只不過偏見在數據中會藏得更加隱密。
舉例來說,有一組我預計更新的數據,其中稅率這一項是 2016 年的資料,在此我提供三項能夠有效調整稅率的方法,從價值最低的產業內所有公司的平均有效稅率,到產生更高價值賺錢的公司的加權平均有效稅率。如果你鐵了心一定要證明美國的公司不會繳納他們應該繳納的稅,你的報告裡就只用寫第一位數,後面的數字提都不要提。反之,如果你想表達美國公司繳的稅只多不少,你就要把數字全部寫出來。
就是因為這個原因,我才不會聲稱自己毫無偏見,但是我會儘量給大家提供多一點選擇 ,你們自己來決定哪個最符合自己的預期。
3. 數據使你保持理智:盡可能讓自己保持理智是人類的本性,而數據又剛好能夠滿足這個需求。在生活的其他方面,我們通常會將數據和不穩定或無法控制的變數綁在一起來使它穩定。所以,說實話,計算 ROIC 並不能使壞標的變成好標的,就如同你計算利息覆蓋率 (利息覆蓋率 = EBITDA ÷ 利息支出,衡量公司產生的稅前利潤能否支付當期利息的指標) 也無法使需要支付的利息變得更容易支付。
不要誤解我的意思!我內心深處還是一個數據為王的人,只不過我現在對數據的看法比以前更客觀了。我對數據的信仰在我跟它們打交道的經歷中逐漸變得理智,尤其是在目睹無數次數據為使用者調整的例子之後。我只相信我驗證過的數據,我希望你也能這麼對待我網站上的數據。
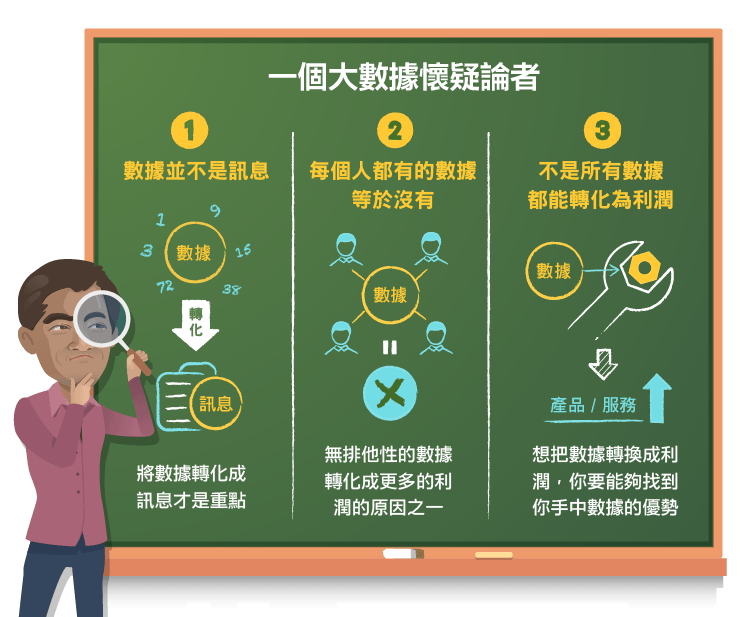
在我使用數據的經驗裡,我最懷疑的是目前最熱門的兩個商業概念,大數據和數據分析。公司的確比先前搜集了更多數據,而且涉及我們生活中的各種領域,並期望利用數據從消費者身上獲得更多利益。在資本主義社會,我對大數據是否能獲利持懷疑態度,原因有三。
1. 數據並不是訊息:數據是在不同的情況下產生。你實際經驗累積的數據比起你預期將要做什麼事情的數據來的有價值。你看好蘋果(Apple, AAPL-US) 、推特 (Twitter) 或者看好整個市場根本毫無用處,這種數據完全不如你買進蘋果、推特的股票紀錄。這一點我們都要警惕,因為現在這種大數據狂熱已經席捲到社交媒體 (從推特到臉書(Facebook, FB-US)),並且已經使用金融數據來產生資料庫了。
另外,隨著我們收集的數據越來越多,值得注意的一點是,數據並不是訊息。實際上,如果數據分析師們有認真工作,那麼將數據轉化成訊息才是重點,而不是只生成看上去很簡潔的圖表或語焉不詳的統計資料。
2. 如果每個人都有數據的話,那等於沒有:數據之所以有價值,是因為在某種程度上數據要有排他性,而且人在處理數據上需要有特殊優勢。這也是為什麼大部分投資者無法將接觸到的數據,轉化成更多利潤的原因之一。
3. 不是所有數據都能轉化為利潤:想把數據轉換成利潤,你要能夠找到你手中數據的優勢。對於提供產品和服務的公司,這意味著他們得改良現有產品/服務,或者從數據中獲得的靈感來開發新產品/新服務。
從上述三點,你可以很輕易的了解為什麼 Netflix 和亞馬遜(Amazon, AMZN-US) 能成為將大數據轉換成巨額利潤的大贏家。他們分析我們 (消費者) 的行動,亞馬遜觀察我們買什麼商品,Netflix觀察我們看什麼內容,這些訊息僅為這些企業獨家所有,而且能用來改良產品服務,使我們能夠帶給公司更多的獲利。出於相同的原因,你也能了解我為什麼說使用大數據來投資,最多只能提供一個短暫的優勢,以及為什麼我願意分享我的數據。
如果你選擇要使用我的數據,我覺得有必要帶你們經歷一次我收集和分析數據的過程,也能給你們提供過程中需要注意的事項。
1. 原始數據:第一步,從收集原始數據開始。我使用的是 S&P Capital IQ、彭博和一系列專業資訊 (Moody’s、PRS 等)。對於公司特定的數據,我篩選公司的唯一標準就是市值不是零,至 2017 年 1 月 1 日符合的公司有 42678 間,這是市場數據 (包括股票價格、市值和利率),但會計數據是搜集近 12 個月內的資料。
2. 分類:我首先按照地緣將這些公司分成了五組,美國、日本、西歐 (包括歐盟和瑞士)、新興市場 (包含東歐、亞洲、非洲和拉丁美洲) 以及澳洲/紐西蘭/加拿大,這是一個基於歷史音速的粗略分組。
接著,我把這些公司分成了 96 個產業,按照原始服務產業和 SIC 代碼分組,每個產業小組內的公司根據地緣再進一步分組。
3. 關鍵數據:我一般不會提供總體經濟數據 (例如利率、通貨膨脹、GDP 成長等),因為這些數據可以在 FRED (the Federal Reserve data site in St. Louis) 找到。我每年年初更新股票風險溢價不僅是為了美國境內的投資者,還為了各地的投資者,下一次更新會在 2017 年 7 月。利用這些公司數據,我會上傳幾十個依照產業分組和地緣分組的指標,包含公司獲利、資金成本、相對風險和一些估值比率。
4. 計算細節:跟數據鬥智鬥勇的經歷中我學到的教訓是,即使計算十分簡單的統計資料,仍然需要做出選擇,但這又會被你個人的偏見所影響。再舉一個例子,為了計算美國鋼鐵公司(United States Steel Corporation, X-US)的本益比,我可以直接將這些公司本益比直接進行平均,但是這樣不僅將小公司和大公司放在了同一個水平線上衡量,還將一些獲利為負的公司從我的樣本中去掉,這在估值中會產生偏誤。
為了解決這個問題,對於產業平均的統計數據,我會將所有公司資料搜集好後才計算比率。例如,計算美國鋼鐵公司本益比的時候,我把所有鋼鐵公司的淨利 (包括賠錢的公司) 加起來,然後再把這些公司的市值加起來,接著用後者除以前者得到本益比。把這些均值看做加權平均,也許這能解釋為什麼我給的數據跟別的服務機構給的不一樣。
5. 報告:我已經絞盡腦汁報告這些數據,以便你可以輕鬆找到你想要的。我還沒有找到完美的範本,但這裡會教你如何找到數據。對於當前的數據 (從 2017 年 1 月) ,你看到分類為風險、獲利能力、資本結構和股利措施的數據,這反映了我選擇公司的財務重點,並依評價分組 (獲利乘數、帳面價值乘數和營收乘數) 。我也保存著以前的數據 (最遠到 1999 年) 。不幸的是,由於在過去 20 年中我不得不多次切換原始數據來源,所以隨著時間的推移,數據並不完全可比,因為產業分組和數據度量隨時間變化而不同。
6. 方法:有兩種方法可以獲取數據。美國的數據,我有 html 的版本,你可以在瀏覽器上看到。全球的數據,我有 excel 表單,你可以下載數據。 我強烈建議你使用後者而不是前者,因為你可以操作和處理數據。 如果你對任何變數和我如何定義它們有任何疑問,請嘗試這個鏈接,我總結了我的計算細節。 (編譯 ⁄ Rose)
《Musings on Markets》授權轉載
超好賺!
每天都有任務能拿獎勵,快點擊查看!











避免犯下大錯的簡單概念-別專注於股價的短期波動_-.png)