

1

投資
在一片靜寂的氛圍里,李彥宏小步登場,語氣里帶著點緊張:
大家的期望值,是我們對標 ChatGPT,對標 GPT- 4 ,這個門檻有點高(笑)。
十月懷胎,我們就帶大家來看看這個 AI 大模型文心一言長什麼樣。
GPT- 4 發布一天之後,壓力全部給到百度(Baidu, BIDU-US)這邊。在 2023 年 3 月 16 日的「文心一言AI大模型並發表會上,百度創辦人、董事長兼執行長李彥宏親自登場,展示了備受關注的文心一言的能力,進行現場實測。據介紹,文心一言目前具備五大使用場景、五大能力,包括文學創作、商業文案創作、數理推算、中文理解和多模態產生。接下來就讓我們看看,文心一言究竟可以做到哪些事情吧!
編按:2023/03/20 更新,文心一言預計將於 2023/03/27 正式上線。
文心一言是一個由擺渡推出的多模態大模型。李彥宏開場就展示了文心一言具備的 5 種能力,包括文學創作、商業文案創作、數理邏輯推算、中文理解、多模態產生。文心一言甚至還現場秀了一口接地氣的四川話,現場網友發出一片笑聲。
文心一言擁有優秀的基座:文心大模型 ERNIE 及 PLATO 系列模型。據文心一言的負責人王海峰介紹,文心一言的關鍵技術包括有監督精調、人類回饋的強化學習、提示、知識增強、檢索增強和對話增強。前三項是這類大語言模型都會採用的技術,ERNIE 和 PLATO 中也已經有應用和累積;後三項則是百度已有技術優勢的再創新,也是文心一言未來越來越強大的基礎。
另一方面,文心一言走過了一條填鴨式的中文學習之路。據李彥宏介紹,文心一言大模型的訓練數據包括兆級網頁數據、數十億的搜尋數據和圖片數據、百億級的語音日均調用數據,以及 5,500 億事實的知識圖譜等,這讓百度在中文語言的處理上,擁有了頂尖水平——訓練結果也是顯而易見的,在文學創作、商業文案創作、數理推算、中文理解領域,文心一言已經實現了智能湧現。
文心一言真有那麼神?
根據展示,在文學創作場景中,文心一言根據對話問題將知名科幻小說《三體》的核心內容進行了總結,還提出了多個續寫《三體》的建議角度。對於較新的《三體》電視劇版本,文心一言也有相應數據,能夠回答出演員表、演員特徵等事實性問題。
再來可以看看 GPT-4 產生的答案:
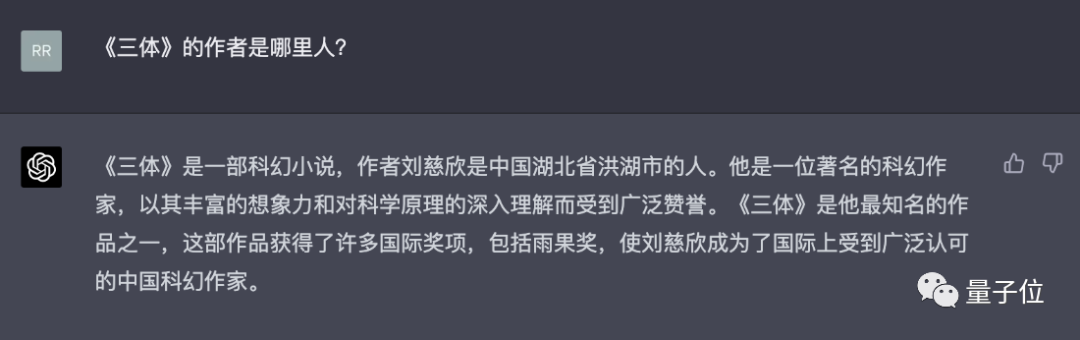
編按:GPT-4 給出的答案是錯的。
在商業文案創作場景,文心一言展示了常見的為公司起名、寫 slogan、寫新聞稿的能力。李彥宏稱,這歸功於文心一言大模型龐大數據規模,包括兆級網頁數據,數十億的搜尋數據和圖片數據,百億級的語音日均調用數據,以及 5,500 億事實的知識圖譜等。他還表示,有研究表明,數據規模足夠大,參數達到千億級,大模型就可能發生「智能湧現」,即使在沒有專門訓練過的領域,也能湧現出知識理解和邏輯推理能力。
這邊文心一言也不是隨便取名的:

再來也看看 GPT-4 給出的答案:

在數理邏輯推算上,文心一言回答了經典的「雞兔同籠遊戲」問題,不僅可以理解題意,還列出了解題思路,一步步算出正確答案。同時,它還辨識出其中一道題目出錯了。李彥宏稱,文心一言已具備了一定的思維能力,能夠學會數學推演及邏輯推理這類相對複雜任務,但現階段準確率還不是 100% ,還需要更多時間來學習和成長。

在中文理解能力方面,文心一言回答了「洛陽紙貴」的意思、當時洛陽紙到底多貴,以及這個成語在現在的經濟學原理里對應的理論等問題。這主要體現了文心一言作為以中文為基礎的大語言模型優勢,不過李彥宏也稱,該模型目前對英文語種和代碼場景的訓練還不夠多,表現還不夠好。

在多模態產生方面,李彥宏展示了文心一言產生圖片海報、四川話音樂以及音視圖結合的影片能力。不過,由於產生影片成本比較高,還沒有對所有用戶開放,未來會逐步接入。

正如 ChatGPT 脫胎於 OpenAI 的 GPT 系列,百度(Baidu, BIDU-US)這次推出的文心一言(ERNIE Bot),背後也正是基於文心大模型技術打造。據王海峰介紹,文心一言主要脫胎於兩大模型:
百度 ERNI E系列知識增強千億大模型,以及百度大規模開放域對話模型 PLATO。
在此基礎上,主要採用了六項核心技術。其中三個是廣為人知的大模型技術,包括有監督精調、人類回饋強化學習(RLHF)和提示構建。
p.s. 人類回饋強化學習也是 ChatGPT 的關鍵技術。
另外三個,則是「百度比較有特色」的技術,包括知識增強、檢索增強和對話增強技術。
首先來看與 ChatGPT 類似的技術:有監督精調、RLHF 和提示構建。有監督精調,尤其指中文方面的數據精調。百度基於對中國語言文化和中國應用場景的理解,篩選了特定的數據來訓練模型。至於人類回饋的強化學習(RLHF)和提示構建,操作上也與 ChatGPT 大差不差。隨後是百度提出的、用於進一步改善模型效果的技術。知識增強,包括知識內化和知識外用兩個部分。其中,知識內化即將知識「滲透」進模型參數中;知識外用指的是模型可以直接使用外部的知識。檢索增強,則與百度搜尋引擎累積的檢索技術有關。百度將把檢索技術和產生技術結合起來,先對內容進行檢索後,將比較有用的部分用於產生,再整合輸出結果。最後是對話增強部分,包括之前百度累積的記憶機制、上下文理解和對話規劃等技術:
概括來看,文心一言表現出的能力,被李彥宏稱為「智能湧現」:
當參數達到千億量級,訓練語料達到足夠多的情況下,這種現象就會發生。
目前,百度擁有的 AI 技術可以分為四個部分,晶片(昆侖芯)、框架(飛槳)、模型(文心)和應用。之所以軟硬體都要布局,百度稱,是為了降低成本:
產生式AI需求的算力非常高,費用相當昂貴。
因此,如果在四層架構之間相互(進行協同優化,就能讓它的效率比別人更高,從而顯著降低成本。李彥宏認為,這也正是百度的優勢所在:
四層都有領先產品的公司,絕無僅有。
《36氪》授權轉載
【延伸閱讀】
超好賺!
每天都有任務能拿獎勵,快點擊查看!














