1
產業
在上一篇機器學習的介紹中,我們了解了何謂人工智慧、機器學習以及深度學習,但在開始程式教學前,我們必須先從機器學習的整個架構流程開始教起,不然在撰寫程式時,一定會不知道接下來該進行哪一個步驟,這樣就大大降低了學習的功效,也無法確保模型的正確性,那我們就開始今天的解說吧!
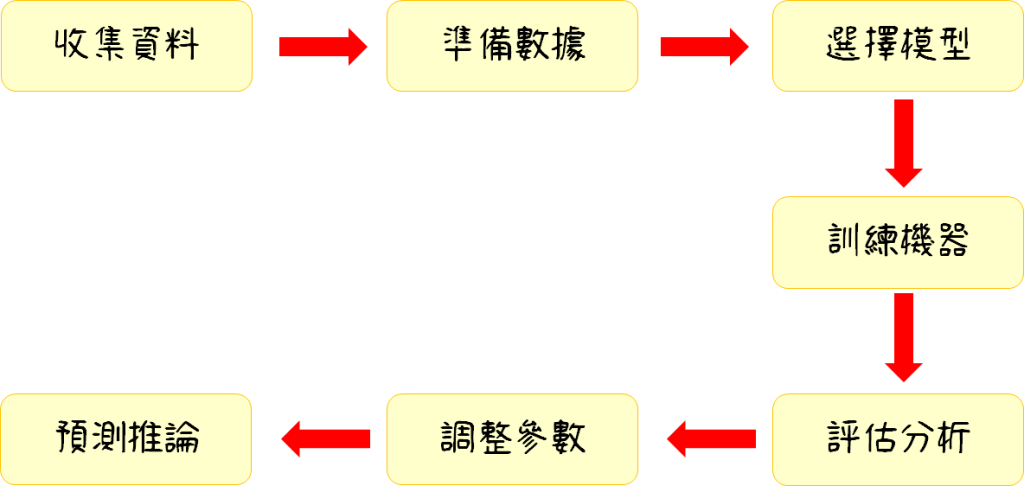
只要是建立於機器學習之中的,包括深度學習,其架構流程都是依照這 7 大步驟下去運作,唯有每一步驟都做得確實,程式的運作才會成功,所以這 7 大步驟相當之重要,缺一不可。
收集資料
首先,收集資料就是將我們與目標相關聯的資料做一個抓取,以預測股市股價來說,我們所需的資料當然就是開高低收、技術指標、財務指標、籌碼指標等等,根據你所要分析的目標是長中短期,去加入你所需要的數值,這就是收集資料。
準備數據
當然,資料收集好後,沒那麼簡單就可以拿給機器做學習,我們還需要進行數據的整理,篩選重要的特徵值,分割成訓練集跟測試集,如果每個指標的數值範圍都不一,我們還需要進行正規化,正規化又分成了「max-min 法(最大最小正規化)」、「z-score 法」等等方式。
選擇模型
當數據都進行整理後,接下來就是要選擇訓練用的模型,像是決策樹、LSTM、RNN 等等都是機器學習中常使用的訓練模型,其中目前較常拿來訓練股市的是「LSTM」,中文叫做長短期記憶,是屬於深度學習中的一個模型。
訓練機器
選擇好訓練模型後,當然就是要將訓練集資料丟進去模型中做訓練拉,例如 LSTM,我們需要設多少神經元、要跑幾層等等都會影響模型訓練出來的結果,這部分只能靠經驗跟不度嘗試去學習了,或是上網多爬文看別人怎麼撰寫訓練模型。
評估分析
當模型訓練完成後,接下來就是判斷該模型是否有過度擬合(overfitting),這裡就是帶入測試集的資料進行評估,也可以嘗試利用交叉驗證的方式進行模型的擬合性判斷,以及利用 RESM、MSE 等統計計算來判斷模型的準確度。
調整參數
到這大致上模型已經完成了 90% ,最後的一步就是進行參數的微調,我們也稱為「超參數 (Hyperparamters)」,讓整個模型更加的精準,但也不能過度的調整,因為會造成 overfitting 的結果,這個取捨就只能依照無窮盡的反覆迭帶去尋找了,這部分也是相對較耗時間的地方。
預測推論
到此,模型已經正式完成,但對於全新沒影響過的數據則是一個未知數,由於在上方訓練模型中,我們不論是訓練集或是測試集都是被模型所影響過的,如果過度擬合,那麼未來丟入新的資料就很可能無法那麼精準,這部分就只能不斷丟入新資料來推論我們模型的預測能力是否有泛化。
今天稍微介紹了一下機器學習整個流程的大綱,但實際做起來絕非三言兩語能夠完成,或許你對今天介紹中的專有名詞感到相當陌生,但沒關係,這部份我們往後介紹時會一一做說明,在這只需要先了解,我們機器學習的這 7 大步驟是缺一不可,缺少其中一步的話,我們就無法保證我們訓練模型的正確性,對於重要研究或報告來說,正確性往往比準確性來的重要。
以上為個人觀點,如有不對可提出糾正,如有更多看法的也能留言一起討論喔!
《陳陳的嘉理》授權轉載
【延伸閱讀】
超好賺!
每天都有任務能拿獎勵,快點擊查看!




商品期貨基本面分析:供需平衡表_-.png)