
1

投資
 David Merkel
David Merkel
以下的這段話在2004年的5月28日刊登於RealMoney:
投資策略
資料探勘試圖賦與數據一個或許不存在的顯著答案。技術分析可能涉及資料探勘。運氣可以使一個方法看起來比實際上還要有用。
投資者往往會傾向使用量化分析來投資。這些方法包括基本面分析或技術面分析,並且時常可以看到過去預估未來可能會有不錯的結果,但當一般投資大眾(或專業投資人)試了這些方法,並未達到預期當中的績效。這是為什麼呢?
這有許多原因,但我認為只有一個最重要的原因:資料探勘。我稍後會定義資料探勘的意義並給你幾個方法來避免,不管你使用的是量化分析或者是創造一個新的量化分析方法。
我從未取得我的博士學位,但我拿到了經濟計量學的研究所學位。在求學期間,他們教導我的其中一件事就是對資料過度解釋所帶來的危機。可能有經濟學家甚至會說,“如果我能夠將資料嚴刑逼供,我就可以讓它招供所有事情”。
當量化分析師在挖掘數據時,他會重複使用不用的假設來測試相同的數據。當他發現有相當顯著的正相關時,他就會停止再用其他的假設來測試。他可能會開始對這個假設相當有信心,認為這個假設能夠得到重要的結果。
資料探勘(Data-mining),或有人稱它為特定搜尋(specification searching)試圖賦與資料一個顯著的答案,不管它是不是真的存在。財務數據相當地繁雜,它有太多太多瑣碎的資訊,時常不是只有單一個訊號。在每一次分析數據時都有很大的機率可能將不起眼的資料解釋為單一訊號。對資料的過度解釋增加了分析師將雜訊判斷成為重要訊號的機率。

可以用Michael O’Higgins的著作:《戰勝道瓊(Beating the Dow)》作為例子,在這本書當中他介紹了他廣為流傳的“道瓊狗”理論。或著是也可以看看James P. O’Shaughnessy的《What Works on Wall Street》在這兩本書當中,運用不同的假設試著去擠出一個在過去製造出最好績效的方法。
道瓊狗理論的基本理念是買入便宜、大型的股票。但在測試多種不同的假設之後,廉價指標是會改變的。哪一個才是最好的呢?是P/B、盈餘、銷售額、現金流量、股價還是股利殖利率呢?另一個會變動的因素是要選擇哪些股票。要選前十名、前五名、第一名或者是第二名呢?要多久更新資料呢?是一年、一季還是一個月?有這麼多的排列組合,這樣的策略還是有可能不小心將績效最好的排除。
What Works on Wall Street當中也有一些不錯的核心概念(但它名字似乎取錯了,應該要改成What Has Worked on Wall Street,但如果改名的話可能沒辦法賣得這麼好了)。它的核心理念:買進價格正成長和盈餘產生動能的便宜股票。但在這個方法中,有許多評估便宜的指標和分析動能的方法,足以測試50種不用的理論。雖然它的基本觀念合理,但是能夠獲勝只是偶然的結果。
Bloomberg有一個技術分析的回測函數–BTST。它使用8種不同的技術分析方法並顯示每一項方法在過去的績效如何。測出來的結果是有一些方法是有效的。即使分析師用隨機資料取代實際的價格資料,這個函數還是有可能會選出其中一個被認為為是獲利情況良好的方法。
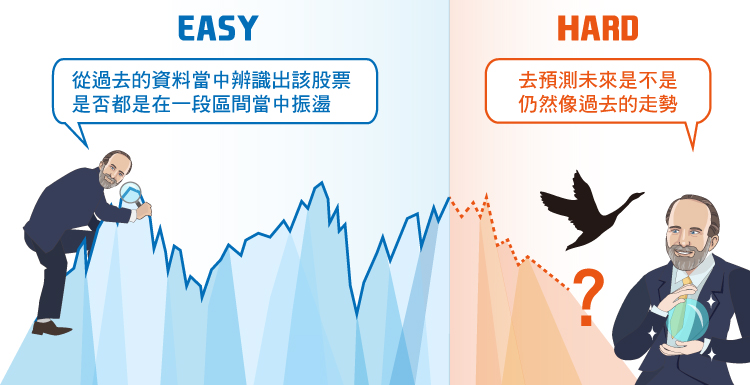
我在一些“服務”當中也看到了數據探勘被濫用的情況,這些服務提供辨認“區間震盪股(rolling stocks)”。這些股票似乎僅在一個區間之內波動。這使投資人有機會在區間的下限買入這檔股票,並在區間的上限將股票賣出,這樣就能夠快速的賺得差額。這個方法最大的問題是從過去的資料當中辨識出該股票是否都是在一段區間當中振盪很容易,但是很難去預測未來是不是仍然是這樣子的走勢。遵從這樣子的指示的確是有可能有好的績效,但是如果情況突然發生轉變,你可能會有巨額損失的危險。
股票的績效能比債券好上多少,受到許多社會上以及政治上的因素影響。人們不可能無止盡地投資下去,他們至少要留一些錢以供日常的生活所需,因此長期的平均回報並不代表投資人平均能夠達到的報酬。評價的問題,和債券的報酬率一樣。在設定資產配置時,忽略股票評價和債券報酬率會使投資人高估了股票和債券,它們可能在過去有好的表現,但是在接下來的10年不一定會能夠產生一樣好的表現。
在過去的工作中,我曾為一位有壽險客戶的資產管理師作數據分析。公司有數種衍生性金融商品,這使我們使用多樣的不同信用風險作為降低風險的一種工具。我時常會看到過去績效的相關矩陣,因為不同風險的資產組合而使波動的程度有相當大的減緩。我想問站在賣方的量化分析師相關矩陣究竟能有多穩定,在1998年,爆發長期資本管理公司(Long Term Capital Managemtnt,LTCM)危機時,他們給風險最高的固定收益資產多高的相關性,而復甦後的相關性又是多少。絕大部份的時間,他們都沒有考慮到這個問題。
如果你看到一個分析師總是依賴著某種基於平均數-變益數框架的報酬相關矩陣,一定要特別小心。我在這裡最喜歡舉的例子就是組合式基金(fund-of-funds),不管是CTA(商品交易顧問基金)或者是共同基金。以下是幾個主要的原因:
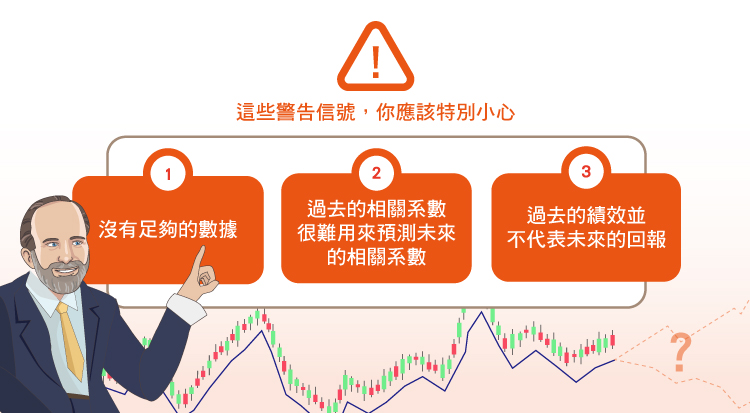
第一,沒有足夠的數據來估計它的相關矩陣。就算那些沒有經驗的從業者不知道每一個他們所計算出來的相關係數都需要一小段的期間資料,他們還是這樣做。舉例來說,如果是一個10個收益序列的相關矩陣,那麼它至少需要46段期間的資料,如果能夠有70段期間才能夠達到統計上的可信度。
第二,即使它有足夠的資料來計算相關系數,也達到了可信度,這個產生相關係數的財務過程仍然相當不穩定。很難用過去的相關系數來預測未來的相關系數。
第三,“過去的績效並不代表未來的回報”。不管是報酬率或者是報酬的變益數都一樣。這並不讓人意外,歷史上的平均報酬除以報酬的變動對一個想要得到和過去差不多報酬的經理人來說並不是一個預測未來的適當因子。簡而言之,我認為夏普指數(Share Ratio)並不能真正產生報酬或降低風險。效率前緣(efficient Frontier)雖然可以呈現一條漂亮的曲線,但當它的參數是參考歷史資料而得的時候,無法真的使資產配置在未來能夠達到最適的風險以及報酬。
另一個資料探勘的反派人物是收益風格分析法(Returns-Based Style Analysis),這個方法假設基金管理人的風格能夠以他的報酬和不同的資產指數的相關性來區分。先暫時不談多元共線性和在受限制的迴歸下無法建立信賴區間的問題,使用短期的歷史數據資料或許能夠看得清過去的情況,但是卻很難將它運用在預測基金經理人未來的績效。簡而言之,過去的關聯性很難用來預測未來的回報。
在金融研究領域來說,只有倖存者才能發表論文,而這些論文需要有統計或者是經濟領域的數據作為支撐,但是這可能因為一些原因或者是結構上的改變而發生變化。資料探勘讓一些名氣較小的學者有發表論文的機會。
在這篇文章的第二部份,我將會介紹一些評估量化分析的實際方法,以及如何避免資料探勘。
《The Aleph Blog》授權轉載
David Merkel
超好賺!
每天都有任務能拿獎勵,快點擊查看!




避免犯下大錯的簡單概念-別專注於股價的短期波動_-.png)










