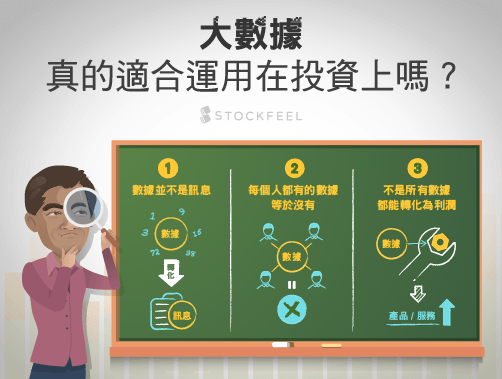
1
產業
近年來,隨著 AI 的崛起,神經網路一詞也不斷出現在人們的視線中。事實上,神經網路並不是什麽新興詞匯。
早在 70 多年前,神經網路就被 AI 前沿的工作人員用來探索人類大腦的運作模式—— 人類大腦裡有著數十億的神經元相互連接,形成錯綜覆雜的生物神經網路,負責處理各種感官數據,並作出相應的應激反應,使我們從不斷嘗試的反饋中總結經驗,收獲新知。同樣,AI 中的「神經網路」也是通過相互連接的不同層面過濾處理大量的數據,通過自我學習,做出相應的預測或模式識別。

如何讓AI理解數學?Facebook神經網路通過「語言翻譯」解數學難題
由於神經網路在 AI 中的決定性地位,以及它面臨各種棘手的問題時表現出的強大到幾乎無所不能的潛力,神經網路被推崇成「無所不能」的存在。
其中,最具有代表性的問題就是模式識別(pattern recognition)問題。或許你沒聽說過這個專業術語,但你一定熟悉通過模式識別衍生出許許多多功能強大的應用:比如,如何讓 AI 給出活用的解答而不是呆板的翻譯,如何讓手機相冊自動識別並標記照片中反覆出現的面孔,甚至包括讓 AI 學習下圍棋並戰勝世界冠軍等等,這些都離不開模式識別技術的強大助推。
模式識別,通過計算機技術自動地或半自動(人機交互)地實現人類的識別過程。這裡,模式是這樣定義的:為了能讓機器執行識別任務,必須先將識別對象的有用訊息輸入計算機。為此,必須對識別對象進行抽象,建立其數學模型,用以描述和代替識別對象。
而模式識別是指對表徵事物或現象的各種形式的(數值的、文字的和邏輯關係的)訊息進行處理和分析,以對事物或現象進行描述、辨認、分類和解釋的過程,是訊息科學和人工智能的重要組成部分。
模式識別主要包括兩種方法:
1.數理統計方法。 統計方法是發展較早的方法,也是應用最廣泛的一種方法。是將被處理對象進行數位化,通過轉化成計算機可以分析識別的數字信息,對樣本進行特徵值的抽取,將輸入模式從對象空間映射到特征空間。這樣一來,模式便可用特徵空間中的一個點或者一個特徵向量表示。
2.句法方法。其基本思想是把一個模式描述為較簡單的子模式的組合,子模式又可描述為更簡單的子模式的組合,最終得到一個樹形的結構描述,在底層的最簡單的子模式稱為模式基元。其基本思想是把一個模式描述為較簡單的子模式的組合,子模式又可描述為更簡單的子模式的組合,最終得到一個樹形的結構描述,在底層的最簡單的子模式稱為模式基元。
然而,看似功能強大、覆蓋面廣的模式識別在面對高數里覆雜的數學符號時,比如微積分裡的積分或常微分方程計算,卻望而卻步。

如何讓AI理解數學?Facebook神經網路通過“語言翻譯”解數學難題
通過分析上述的模式識別的方法,我們可以簡單推出,神經網路之所以在解決數學問題方面止步不前,主要障礙來源於數學問題的本質—— 數學需要的是精確的答案,而神經網路對訊息的處理方面更擅長的是概率。
他們往往在給定的大量數據下進行模式識別——比如說在翻譯時,在給定的多種的可能的翻譯結果中,辨別哪種翻譯的更接地氣;或者在給定的不同的照片中,標記出人臉,對比相似度,圈出出現概率高的面孔——並根據這些高概率出現的結果,匯總出最有可能出現的模式,並將這種模式定義為新的模式。以其高概率出現的可能性,來進行對未來事件的可能預測。
當然,快速發展、不斷完善的神經網路並不容許它在數學問題上存在持續的缺陷。去年年底,兩位 Facebook 人工智能研究小組的計算機科學家——Guillaume Lample 和 Francois Charton,成功地探索出了用神經網路解決符號數學問題的一種方法。
這個開發出的強大的新程序充分利用了神經網路的一個主要優勢:它可以完善自己的隱式規則。
斯坦福大學(Stanford University)的心理學家傑伊·麥克萊倫德(Jay McClelland)曾說,「規則和例外之間沒有區別」。在不斷嘗試「例外」的過程中,人們可以學習並總結出解決相似問題的通理通法,而將這種通法視為「規則」,並運用「規則」去解決更多的「例外」。在不斷解決「例外」的過程中,「規則」也會隨之完善。
而程序所構建的神經網路,只是模擬了人們在學習數學時在「規則」和「例外」之間不斷轉化的模式。這意味著程序在解決問題時,並不會遇到最難的積分,而是在不斷解決常規問題時,總結出一套「規則」,從而在面對更難的題目時派上用場。
從理論上講,神經網路或許可以推導出不同於數學家們的「規則」。這就好比那個跟自己下了三天三夜圍棋就秒殺人類圍棋高手的 AlphaGo Zero,它的棋法完全悖於傳統,超乎了傳統的認知。
如何讓AI理解數學?Facebook神經網路通過「語言翻譯」解數學難題

值得一提的是,他們的方法並不涉及數字運算或數值近似。相反,他們將覆雜的數學運算問題重新編排,變成了神經網路的拿手好戲: 語言翻譯。
傳統的計算機是非常善於處理數字的。計算機的代數系統,就是將數十種或數百種算法與預置指令生硬地捆綁在一起,而計算機則是按部就班地按照指令進行運算,執行預設好的特定操作。一旦出現背離程序的操作,計算機就只能繳械投降。但對於許多符號問題,它們產生的數值解與工程和物理的實際應用非常接近。
而神經網路則截然不同,他們沒有固定的規則。相反,他們可以訓練大規模的數據集——越大越好——並利用訓練得到的統計數據,對數值解進行很好的近似。在這個過程中,他們學習的是什麽方法,什麽模式能產生最完美的結果。
這在語言翻譯方面表現的尤為出色:在訓練過後,他們並不再是逐字逐句地翻譯,而是能夠協調地翻譯文本中的短語。Facebook 的研究人員認為神經網路這種特性是解決象徵性數學問題的一個優勢,而並不是障礙。它賦予了程序一種解決問題的自由,不同於傳統計算機的刻板。
而這種自由對於某些開放性的問題特別有用,比如積分問題。數學家中有句老話:「微分是門技術,而積分是門藝術」。換句話說,求函數的導數只需遵循一些定義明確的步驟;但是求積分通常需要一些別的東西,在判斷積分方法以及尋找積分項時,它更需要一些接近人的直覺而不僅僅是計算的東西。
Facebook 的研究小組認為,這種直覺可以通過 AI 的模式識別模擬。「積分是數學中最類似於模式識別的問題之一。」Charton 表示。因此,即使神經網路可能不知道函數是什麽或變量是什麽意思,它們也會根據大量數據訓練發展出一種本能,即神經網路也會開始感覺怎麽樣計算可以得到答案。
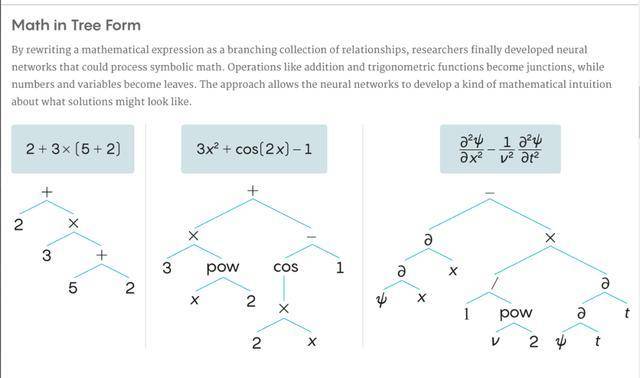
為了讓神經網路像數學家一樣處理數學符號,Charton 和 Lample 首先將數學表達式翻譯成更有用的形式。通過「翻譯」, 他們將覆雜的數學表達式最終翻譯成神經網路可以識別的有效的簡化形式——樹狀圖,來總括表達式裡的運算符號和數字。
其中,運算符號例如加減乘除成為了樹狀圖的枝,而表達式裡的參數(變量和數字)則變成了葉子。通過轉化成樹狀圖, 這能讓覆雜的數學表達式轉化成樹狀圖層層嵌套的簡單運算中,從而可以讓神經網路識別和運算想應的簡化式子,並得到最終的精確結果。
Lample 表示,這個過程與人們解決積分問題,甚至是所有數學問題的過程大體類似。都是通過在覆雜數學表達式中,根據經驗將他們簡化為神經網路以前解決過的子問題。
如何讓AI理解數學?Facebook神經網路通過「語言翻譯」解數學難題
在構建好這個結構以後,研究人員使用一組初等函數生成了幾個訓練數據集,總計約 2 億(樹形)方程和解。然後他們將訓練數據給神經網路,讓神經網路在訓練數據集中對這樣樹狀圖的方程解法有一個初步的認知。
訓練結束後,該看看神經網路現在可以做什麽了。
計算機科學家給了它一個包含 5000 個方程的測試集,這個測試數據是沒有答案的。令人驚訝的是,神經網路成功地通過了測試:它成功地為絕大多數問題找到了正確的解決方案,並且方程解具有很高的精度。它尤其擅長於積分,解決了幾乎 100% 的測試問題。但是,在解決常微分方程時,神經網路表現欠佳。
對於幾乎所有的問題,實驗構造的程序都可以在不到1秒的時間內生成正確的解決方案。尤其是在積分問題上,它在速度和精度上都優於目前流行的軟體 Mathematica 和 Matlab 中的一些內置包。Facebook 團隊報告說,就連證兩個軟體無法解決的一些數學問題,神經網路都可以給出答案。
當然,這也只是一個對未來的展望而已。但毋庸置疑,這個團隊回答了一個存在了幾十年的問題——人工智能能做符號數學嗎? 而答案是肯定的。他們在 AI 探索符號數學的道路上邁出了顯著的一步。麥克萊倫德說:「他們確實成功地構建了神經網路,並且可以解決超出機器系統規則範圍的問題。」
儘管得出了這些結果,Mathematica 開發公司 Wolfram 的負責人,數學家羅傑·格蒙森(Roger Germundsson)還是提出了異議,他表示,實驗中只是拿了 Mathematica 的部分功能和神經網路作了簡單粗暴的比較。
這種比較局限於 Mathematica 特定的指令,比如「integrate」指令被用於求取積分,「DSolve」指令被用於解決微分方程——但事實上,Mathematica 用戶還可以使用其他上百種的方法和指令去解決一個較為覆雜的方程。
Germundsson 還注意到,儘管實驗中所給的訓練數據集非常龐大,但是所包含的方程都只有一個單一的變量,並且只是設計初等函數的運算。「這種方程在可能涉及到的方程運算中只能占到極小的部分。」他說。這個神經網路沒有測試物理和金融中經常使用的更覆雜的函數,比如誤差函數或貝塞爾函數。(對此,Facebook 團隊表示,在之後的測試中,可能只需要在訓練神經網路時,給訓練集做幾次非常簡單的修改。)
加州大學聖巴巴拉分校(University of California, Santa Barbara)的數學家弗雷德里克·吉布(Frederic Gibou)研究過用神經網路求解偏微分方程的方法,他並不認為 Facebook 小組的神經網路是絕對可靠的。「研究人員需要有信心,如果神經網路可靠,它就可以解決任何形式的方程。」
也有其他批評者指出,Facebook 小組的神經網路並沒有真正理解數學,這更像是一種特別的猜想,而非實際的解決方法。

如何讓AI理解數學?Facebook神經網路通過“語言翻譯”解數學難題
盡管如此,反對者還是承認新方法是有用的。Germundsson 和 Gibou 相信神經網路將在下一代符號數學求解工具中占有一席之地——但它也可能只是一席之地而已。「我認為它將只是眾多工具中的一個。」Germundsson 表示。
另一個尚未解決的問題是:沒有人真正了解它們是如何工作的,這也是神經網路發展最令人不安的一方面。
在模式識別中,我們只需要將訓練數據集在一段輸入,相應的預測數據集就會在另一端輸出,但是並沒有人知道這中間發生了什麽,讓神經網路成為了一個完美的學習者。它理解輸入的公式和算法嗎?還是只是按部就班的按照指令處理數字?
對此,Charton 表示:「我們知道數學是如何工作的,通過使用特定的數學問題作為測試,看看神經網路在哪裡成功,在哪裡失敗,我們就可以了解神經網路是如何工作的。」
他和 Lample 計劃將數學表達式輸入到他們的神經網路中,並跟蹤程序對表達式中的微小變化的響應方式。映射輸入中的變化如何觸發輸出中的變化,可能有助於揭示神經網路的操作方式。
Zaremba 認為這是在測試和確定神經網路是否具有理性,以及是否真正理解它們所回答的問題上的積極探索。「數學問題中很容易變換參數或者其它部分——我們可以通過觀察神經網路在面對改動後的方程後作出的反應來窺測它的運行方式。我們可能會真正了解其中的原因,而不僅僅只是方程的解。」
神經網路探索的另一個可能的方向,是自動定理生成器的開發。「數學家們正越來越多地研究使用人工智慧來生成新的定理和證明的方法,儘管這種技術還沒有取得很大進展。」Lample 說,「這是我們正在研究的東西。」
Charton 描述了他們的方法至少有兩種方法可以推動人工智慧定理的發現。首先,它可以作為一種數學家的助手,通過識別已知猜想的模式來幫助解決存在的問題;其次,這台機器可能會生成一個列表,列出數學家們漏掉的可能可證明的結果。「我們相信,如果你能做集成,你就應該能做證明。」他說。
《虎嗅網》授權轉載
【延伸閱讀】
超好賺!
每天都有任務能拿獎勵,快點擊查看!






打破CEO神話-四項成功領導者的關鍵特質_-.png)