

1

產業

2016 年,DeepMind 的 AlphaGo 在圍棋比賽中以 4:1 擊敗了圍棋世界大師級冠軍李世乭,而後 AlphaGo Zero 更是青出於藍,在三天之內就超越了當時和李世乭對戰的 AlphaGo,而 AlphaGo Model 的核心技術之一,就是 Reinforcement Learning(強化學習)。Reinforcement Learning 是 AI 研究中相當熱門的一個領域,也是我個人認為 AI 能最接近人類學習方式的 Model。
Reinforcement Learning 主要透過和環境的互動來學習,跟人類小孩時一樣,根據當下的處境,小朋友會有不同的行為去嘗試,之後也會因為這些行為得到不同的後果,慢慢的小朋友就會學習起來,哪些行為會造成不良的後果,進而慢慢減少這樣的舉動。
例如明天就要段考了,小強面對書本時有不同的想法,第一次的時候他很努力學習,隔天考試的成績相當優秀,自己也非常開心;但第二次時他覺得麻煩,跑去打電動,導致隔天的考試成績非常糟糕,也讓他失落一整個禮拜,慢慢的,小強就從中學習到,面對段考時必須要認真讀書,這樣更能讓他在考試時獲得比較好的成績,心情也會變的更好。
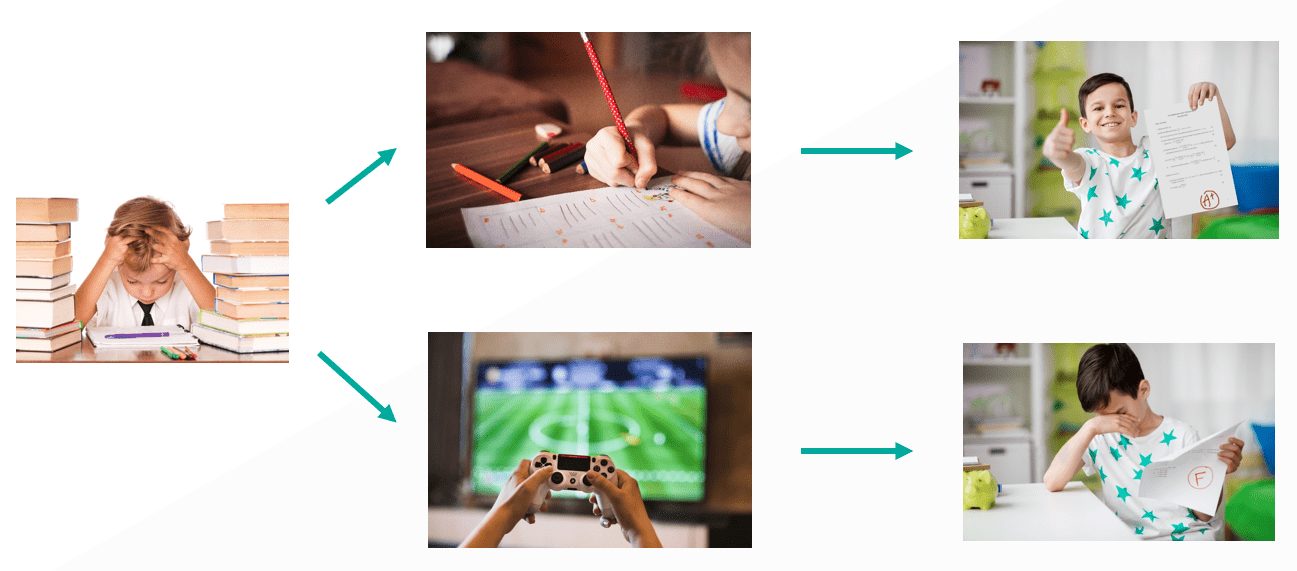
Reinforcement Learning 同樣也是利用這樣的方式學習的,面對一個 Environment(即將段考的環境),AI Model 會做出一個 Action(認真讀書或打電動),這個 Action 會改變整個環境,讓環境進入下一個 State(段考結束),並讓 AI Model 獲得相對應的 Reward(段考成績),根據得到的 Reward,AI Model 會學習並影響下一次的決策,透過不斷的與這個環境互動,不斷的得到各種 Reward,AI Model 即能慢慢成長並學習如何在這環境中生存了。
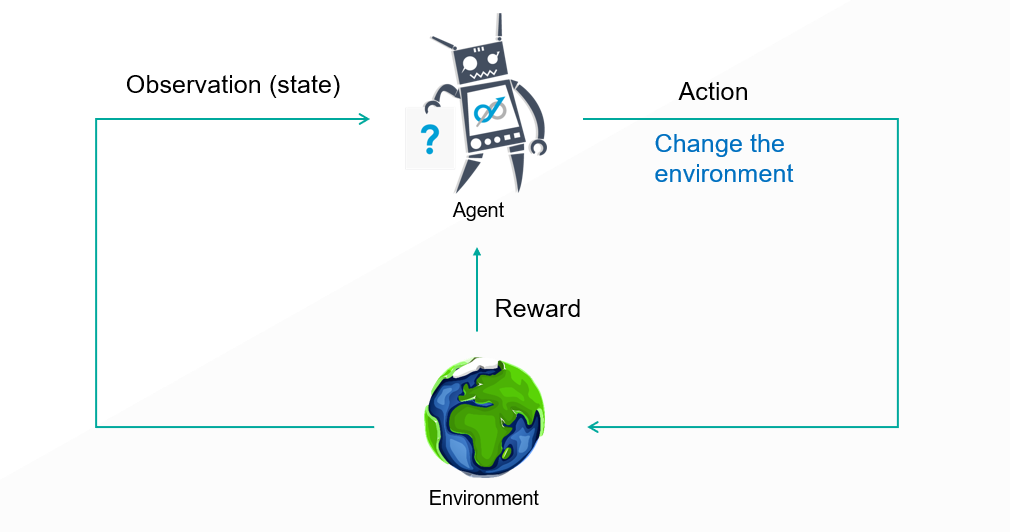
同樣的道理,在期貨市場上,我們也可以為 AI 交易機器人創造這樣的一個環境,讓他以 Reinforcement Learning 的方式學習,而這個環境就如同上面所說,必須包含 Observation、可執行的 Action 範圍、相對應的 Reward 設計。在這樣的 AI 交易架構中,Environment 的設計是相當多變化也是最為重要的一個環節,環境設計的好壞將直接影響整個 AI 交易機器人的績效及穩定性。
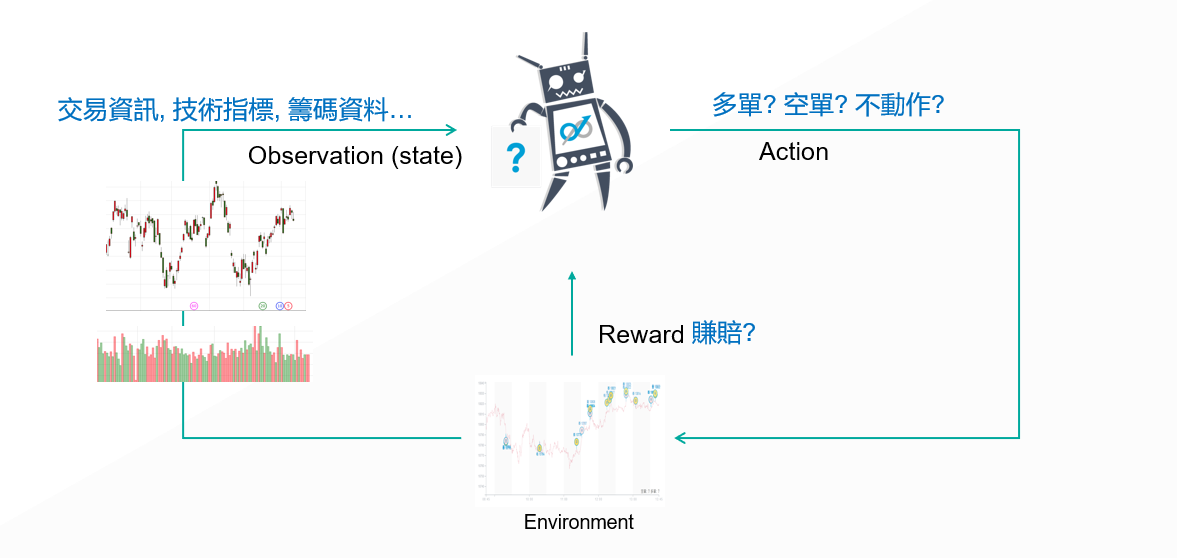
舉個例子,不管是市場上的籌碼資料、技術指標,甚至是消息面的文章資訊等等,都可以打造成 AI Model 的 Observation,讓 AI 交易機器人利用這些資料,執行下單的各種決策;最後,直接以賺賠的點數及面對的風險來決定他能得到的 Reward,就能夠打造一個持續學習進步的 AI 交易機器人來面對期貨市場了。
【延伸閱讀】
超好賺!
每天都有任務能拿獎勵,快點擊查看!










