

1

產業
短短一個月內,中國 AI 新創公司深度求索(DeepSeek)先後發布了 DeepSeek- V3 和 DeepSeek- R1 兩款大模型,成本價格低廉,性能與 OpenAI 相當,讓矽谷震驚,甚至引發了 Meta 內部的恐慌,工程師們開始連夜嘗試複製 DeepSeek 的成果。
Scale AI 創辦人 Alexander Wang在 1 月 24 日的採訪中表示,DeepSeek 在他們的測試里是表現最好的,與美國最好的模型相當。
先前,Alexander Wang 評價說,DeepSeek- V3 是中國科技界帶給美國的苦澀教訓。「當美國休息時,中國(科技界)在工作,以更低的成本、更快的速度和更強的實力趕上。」
此外,中國 AI「洗版」國外各大媒體,它們認為中國大模型的新進展為矽谷敲響了警鐘。
在 5,000 億美元的「星際之門」計劃公布之際,DeepSeek 以極低的價格建立了一個突破性的 AI 模型,而且沒有使用尖端晶片,這讓人們質疑,AI 產業數千億美元資本的巨額投入真的是最有效的方法嗎?
DeepSeek(深度求索)是由中國量化投資企業,幻方量化創辦人梁文鋒於 2023 年成立的一家新創 AI 企業,該企業目前已經推出了包括 DeepSeek-R1 在內的數個模型。而這次 DeepSeek-R1 會如此受到眾人關注,是因為此模型據傳是在不到 600 萬美元的投入和 2,048 片較低性能的 H800 晶片的條件下完成訓練的,而且訓練時間僅僅 2 個月,但是在評分上能和 OpenAI o1 等一種前端模型相提並論。
1 月 24 號,一條發布在匿名平台 teamblind 上的文章瘋傳。一名 Meta 員工稱,現在 Meta 內部因為 DeepSeek 的模型,已經進入恐慌模式。
這位 Meta 員工寫道:
「一切源於 DeepSeek- V3 的出現,它在基準測試中已經讓 Llama 4 相形見絀。更讓人難堪的是,一家僅用 550 萬美元訓練預算的中國公司就做到了這一點。
工程師們正在爭分奪秒地分析 DeepSeek,試圖複製其中的一切可能技術。這絕非誇張。
管理層正為 GenAI 研發部門的巨額投入而發愁。當部門里一個高層的薪資就超過訓練整個DeepSeek V3 的成本,而且這樣的高層還有數十位,他們該如何向高層交代?
DeepSeek- R1 的出現讓情況更加嚴峻。具體細節屬於機密,不便透露,不過很快就會公開了。」
2024 年 12 月 27 日,DeepSeek 推出開源模型 DeepSeek- V3 。當時,聊天機器人競技場(Chatbot Arena)顯示,DeepSeek- V3 在所有模型中排名第七,在開源模型排第一。而且,DeepSeek- V3 是全球前十中 CP 值最高的模型。
不到一個月之後,今年 1 月 20 日,DeepSeek 正式開源 R1 推理模型,允許所有人在遵循 MIT License(注:被廣泛使用的一種軟體許可條款)的情況下,蒸餾 R1 訓練其他模型。
1 月 24 日,DeepSeek- R1 在聊天機器人競技場綜合榜單上排名第三,與頂尖推理模型 o1 並列。
在高難度提示詞、代碼和數學等技術性極強的領域,DeepSeek- R1 拔得頭籌,位列第一。
在風格控制方面,DeepSeek- R1 與 o1 並列第一,意味著模型在理解和遵循用戶指令,並按照特定風格產生內容方面表現出色。
在高難度提示詞與風格控制結合的測試中,DeepSeek- R1 與 o1 也並列第一,進一步證明了其在複雜任務和精細化控制方面的強大能力。
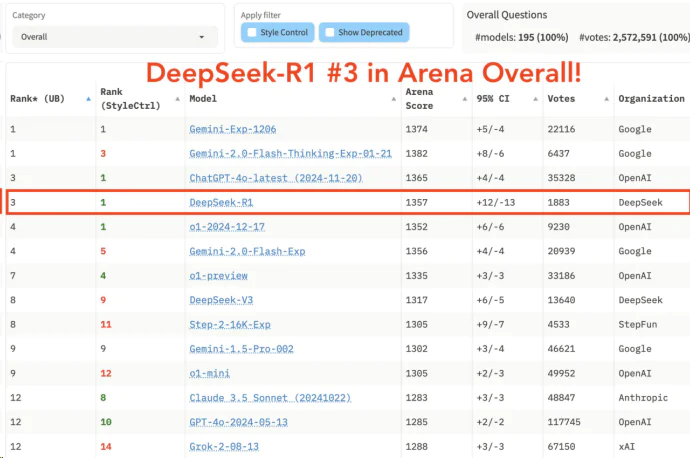
Artificial-Analysis 對 DeepSeek- R1 的初始基準測試結果也顯示,DeepSeek- R1 在 AI 分析質量指數中取得第二高分,價格是 o1 的約三十分之一。
去年 12 月 DeepSeek- V3 發布後,AI 數據服務公司 Scale AI 創辦人 Alexander Wang 就發帖稱,DeepSeek- V3 是中國科技界帶給美國的苦澀教訓。「當美國休息時,中國(科技界)在工作,以更低的成本、更快的速度和更強的實力趕上。」
著名投資公司 A16z 的創辦人馬克·安德森 1 月 24 日發文稱,Deepseek- R1 是他見過的最令人驚嘆、最令人印象深刻的突破之一,而且還是開源的,它是給世界的一份禮物。
1 月 24 日, A16z 合夥人、Mistral AI 董事會成員 Anjney Midha 表示:「從史丹佛到麻省理工,DeepSeek- R1 幾乎一夜之間成為美國頂尖大學研究人員的首選模型。」
對於中國 AI 為何能有如此快速的進展,諾獎得主、「AI 教父」傑弗里·辛頓在 1 月 21 日接受博主 Curt Jaimungal 專訪中表示,中國的 STEM(科學、技術、工程、數學)教育比美國更好,擁有更多受過良好教育的人才,這將為 AI 的發展提供堅實的基礎。儘管美國試圖通過限制(如輝達(NVIDIA, NVDA-US)晶片)來減緩中國的發展,但這只會促使中國加速發展自己的技術,「他們可能會落後幾年,但最終會趕上」。
史丹佛大學和 Epoch AI 的研究人員在 2024 年年中發表的一項研究表明,到 2027 年,最大型的模型的訓練成本將超過 10 億美元。Gartner預測,到 2028 年Google、Microsoft 和 AWS 等超大規模企業僅在 AI 伺服器上的支出就將高達 5,000 億美元。
但 DeepSeek 完全不同,它的訓練成本並不昂貴。Noah’s Arc 資本管理公司表示,DeepSeek- V3 模型有可能徹底改變訓練和推理領域的遊戲規則。
特別是在 5,000 億美元的「星際之門」計劃公布後,DeepSeek 更讓人懷疑,巨額投入這種「大力出奇蹟」的辦法真是最有效的方法嗎?
美股大 V(大量粉絲關注的意見領袖)「THE SHORT BEAR」 1 月 24 日在 X 上發文稱,DeepSeek 給 AI 巨頭們帶來了痛苦時刻,投資者必須對此敲響警鐘。
他說:「如果擊敗 OpenAI 只需要 5,500 萬美元,那麽這個產業的商業化會比很多人預想的要快很多。」
他還指出:「根據紅杉,美國 AI 公司每年必須產生約 6,000 億美元收入來支付其 AI 硬體費用。現在看來,這種冒險行為變得越來越無利可圖。」
著名財經記者 Holger Zschaepitz 1 月 25 日表示,DeepSeek 以極低的價格建立了一個突破性的 AI 模型,而且沒有使用尖端晶片,這讓人們質疑該產業數千億美元資本支出的效用。
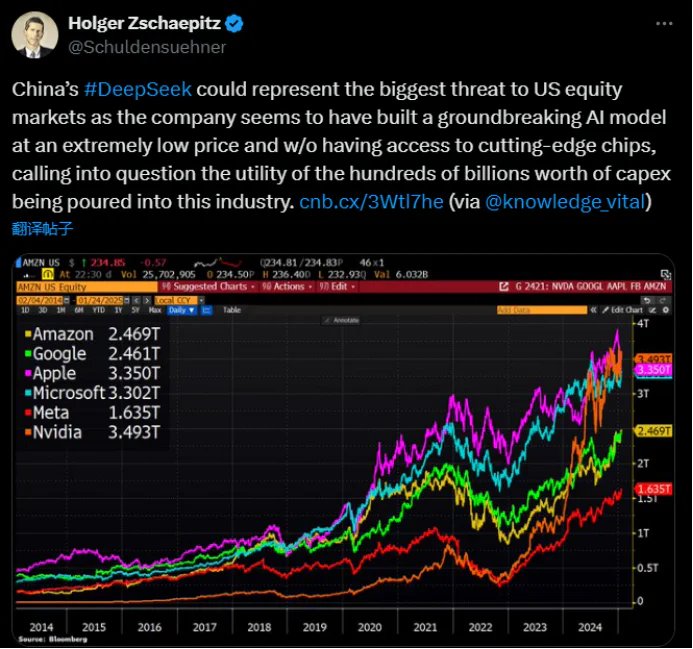
有投資者甚至認為,美股晶片股的股價也會面臨挑戰。
投資者 Geiger Capital 表示,Deepseek 和 OpenAI 一樣好,甚至更好,而且價格只有後者的 3% ……而美國公司卻投入了數千億美元。那麽……納斯達克會怎樣呢?
值得注意的是,DeepSeek- V3 發布後,輝達股價下跌了 2% 。而 DeepSeek- R1 引發海外大討論後, 1 月 24 日輝達股價又大跌了 3.12% 。
如果說 DeepSeek- V3 只是掀起了波瀾,那麽 DeepSeek- R1 則是引發了轟動。最近四天,國外媒體紛紛聚焦 DeepSeek,並一致認為中國大模型的新進展為矽谷敲響了警鐘。
1 月 22 日,美國媒體Business Insider據報導,DeepSeek- R1 模型秉承開放精神,完全開源,為美國 AI 玩家帶來了麻煩。開源的先進 AI 可能挑戰那些試圖通過出售技術賺取巨額利潤的公司。
1 月 24 日,美國媒體 CNBC 推出了長達 40 分鐘的節目,邀請了 Perplexity CEO Aravind Srinivas 來分析為何 DeepSeek 會引發人們對美國在 AI 領域的全球領先地位是否正在縮小的擔憂。
英國《金融時報》 1 月 25 日據報導,中國小型 AI 新創公司 DeepSeek 震驚矽谷。報導聚焦資源更豐富的美國 AI 公司能否捍衛自己的技術優勢。

報導援引加州大學伯克利分校 AI 政策研究員 Ritwik Gupta 稱,DeepSeek 最近發布的模型表明「AI 能力沒有護城河」。Gupta 補充說,中國的系統工程師人才庫比美國大得多,他們懂得如何充分利用計算資源來更便宜地訓練和運作模型。
《虎嗅網》授權轉載
【延伸閱讀】
超好賺!
每天都有任務能拿獎勵,快點擊查看!















