

1

產業
最有希望超越 GPT- 4 的模型來了 —— 美國矽谷時間 12 月 6 日上午,GoogleCEO 劈柴正式宣布,「大殺器」 Gemini 1.0,正式上線。
Gemini 是一個原生多模態大模型,Google 在 2023 年 5 月的 I/O 大會宣布開始研發後,Gemini 的傳說不斷:將 Google 大腦和 DeepMind 部門合併,數百人攻堅,幾乎耗盡 Google 內部計算資源…… 如此種種,只為和 OpenAI 一戰。
但一直等到大半年後,OpenAI 的 GPT- 4 上線,GPT 商店也把矽谷炸了一圈,Gemini 才在千呼萬喚中面世。
 △圖源:Google
△圖源:Google
一個月前,輝達(NVIDIA, NVDA-US)的資深科學家 Jim Fan 就為 Gemini 捏了把汗:「人們對 GoogleGemini 的期望高得離譜!」
他表示,Meta 要驚艷世界的話,只要讓 Llama 3 開源就好了。但 Google 想要重奪當年 AlphaGo 的輝煌,Gemini 不僅要 100% 達到 GPT- 4 的能力,還要在成本或速度上比 GPT- 4 更好。
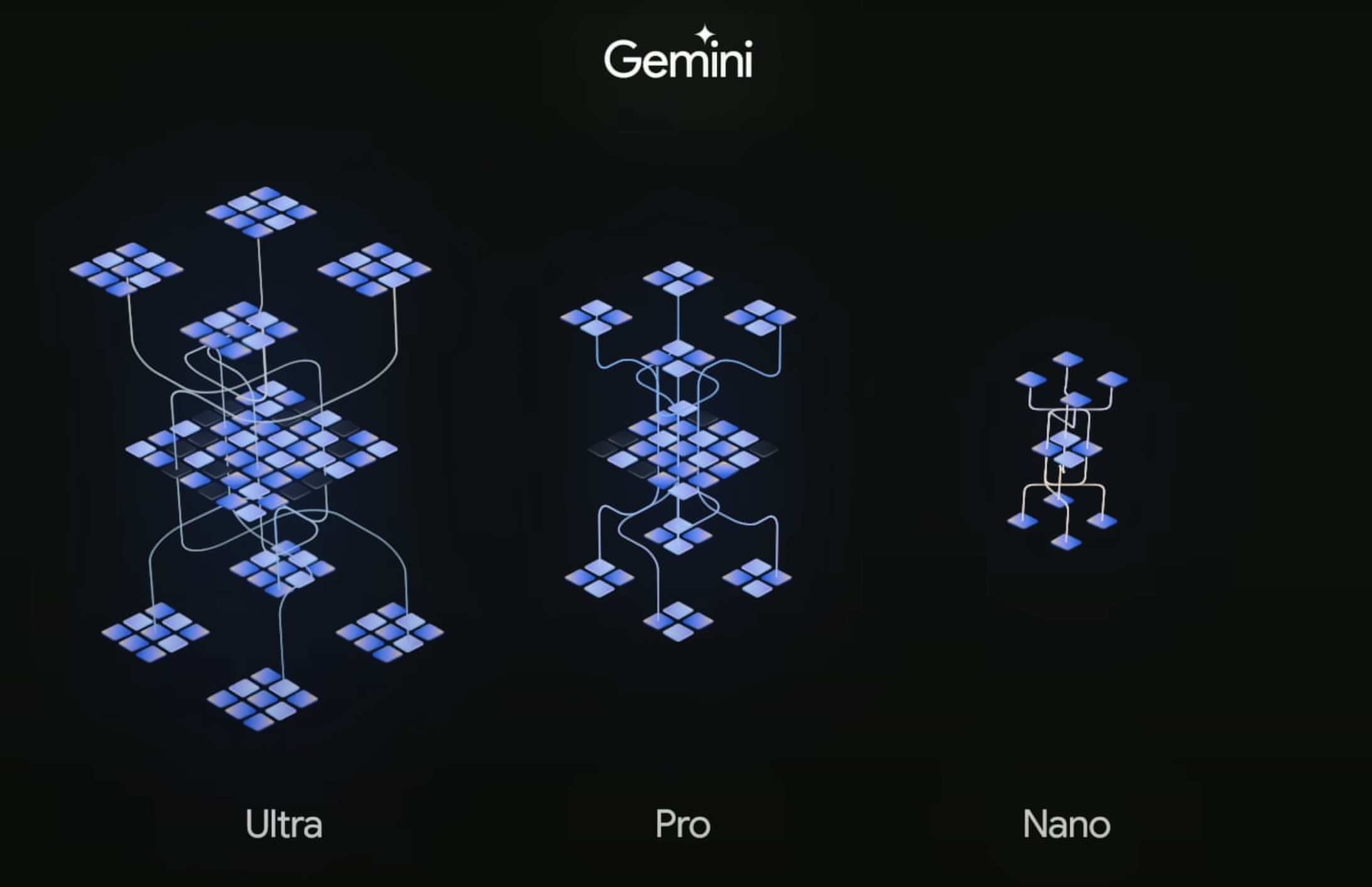
這次發布中,Gemini 終於揭開了面紗 —— 展現了其文本、圖像、影片、音樂和代碼的五大能力,一口氣推出了大中小三個版本,從雲上到手機、平板都可以跑。
並且,Gemini 還有大量的酷炫用例:AI 對一段影片可以做出準確反應,AI 能和你玩你畫我猜…… 簡單來說,越來越像一位真正的人類助手了。
Gemini 1.0 上下文窗口為 32k ,基於 Google 自家的 TPUs v4 和 v5e 進行大規模訓練。這次,Google 順勢推出了新的 TPU 系統 Cloud TPU v5p,希望為訓練 AI 模型的客戶提供支持。
 △Google 數據中心內,一排 Cloud TPU v5p AI 加速器超級電腦
△Google 數據中心內,一排 Cloud TPU v5p AI 加速器超級電腦
AI 圈子里,也是一片相愛相親的景象。Gemini 官宣發布後,甚至不少 OpenAI 的研究員也都發文祝賀 Google
「Gemini,從第一天起就是多模態大模型 —— 跨越文本、 圖像、 影片、 音樂和代碼的無縫推理。」Google 官網路上,這是介紹 Gemini 的第一句話。
這是 Gemini 1.0 最重要的特點:一位更強大的 「全能選手」。
如果和 OpenAI 做對比,OpenAI 的 GPT- 3.5 一開始是純文字的大語言模型,到 GPT- 4 才上了視覺等多模態能力,更像是組件的拼裝,好比先學了語文,再學數學。
但 Gemini 從第一天起就設計成原生多模態結構,相當於 「所有科目一起學」。這其實也是人類認識世界的方式。這意味著,Gemini 可以抽象和理解、操作和組合不同類型的資訊,包括文本、代碼、音樂、圖像和影片等等。
一個直觀的例子是,在理解圖像資訊時,Gemini 基於圖像就可以馬上進行理解。但如果是非原生多模態結構模型上,就需要先借助 OCR(光學字符識別技術)先 「認出來」 圖里是什麼 —— 轉成文本,再放到語言模型中進行語義理解。
Gemini 可以做到端到端的理解,資訊不會在 「轉錄」 過程中丟失。正因如此,Gemini 的應用實例演示顯得尤為絲滑:
 △圖源:Google
△圖源:Google
演示者一邊畫畫,Gemini 一邊辨認,認出了剛開始的曲線形狀。畫出鴨子後,Gemini 也能馬上識別 「鴨子是藍色的,正在水里遊泳」。
Gemini 幾乎是即時就完成辨別,並且用自然、流利的語音和演示者對話。
 △圖源:Google
△圖源:Google
在演示者拿出藍色的橡皮鴨實物後,它甚至還會幽默地打趣:「看來藍色的鴨子比我想像中更常見。」
在通用的文字聊天場景里,Gemini 聰明了不少。在演示影片里,Gemini 挺像《Her》裡的高級人工智慧,可以與人類自如地進行交互。
在一個實例中,演示者向 Gemini 詢問關於女兒生日派對的靈感。Gemini 先是詢問演示者:「可以告訴我她對什麼東西感興趣嗎?」
得到足夠的資訊後,Gemini 自行撰寫了 PRD(產品需求)文件,並且開始不再以文本形式回覆 —— 而是迅速寫代碼,幫用戶定制了一個圖文並茂的小組件。上面包含建議的派對主題、活動、食品建議等,讓演示者在上面滑動,查看自己最感興趣的選項。
辨認環境、物體等等場景,Gemini 也不在話下。給它一張充滿陽光的房間照片,Gemini 還可以推理出來這個房間是朝南朝北,甚至告訴你房間里的植物應該要怎麽照顧。
之所以能夠做到更自然的交互,和 Gemini 的原生多模態架構密不可分。
Google 解釋了部分的訓練細節。比如,Gemini 的團隊從一開始就針對不同的模態進行預訓練,然後再使用額外的多模態數據對其進行微調,以進一步提升其能力。
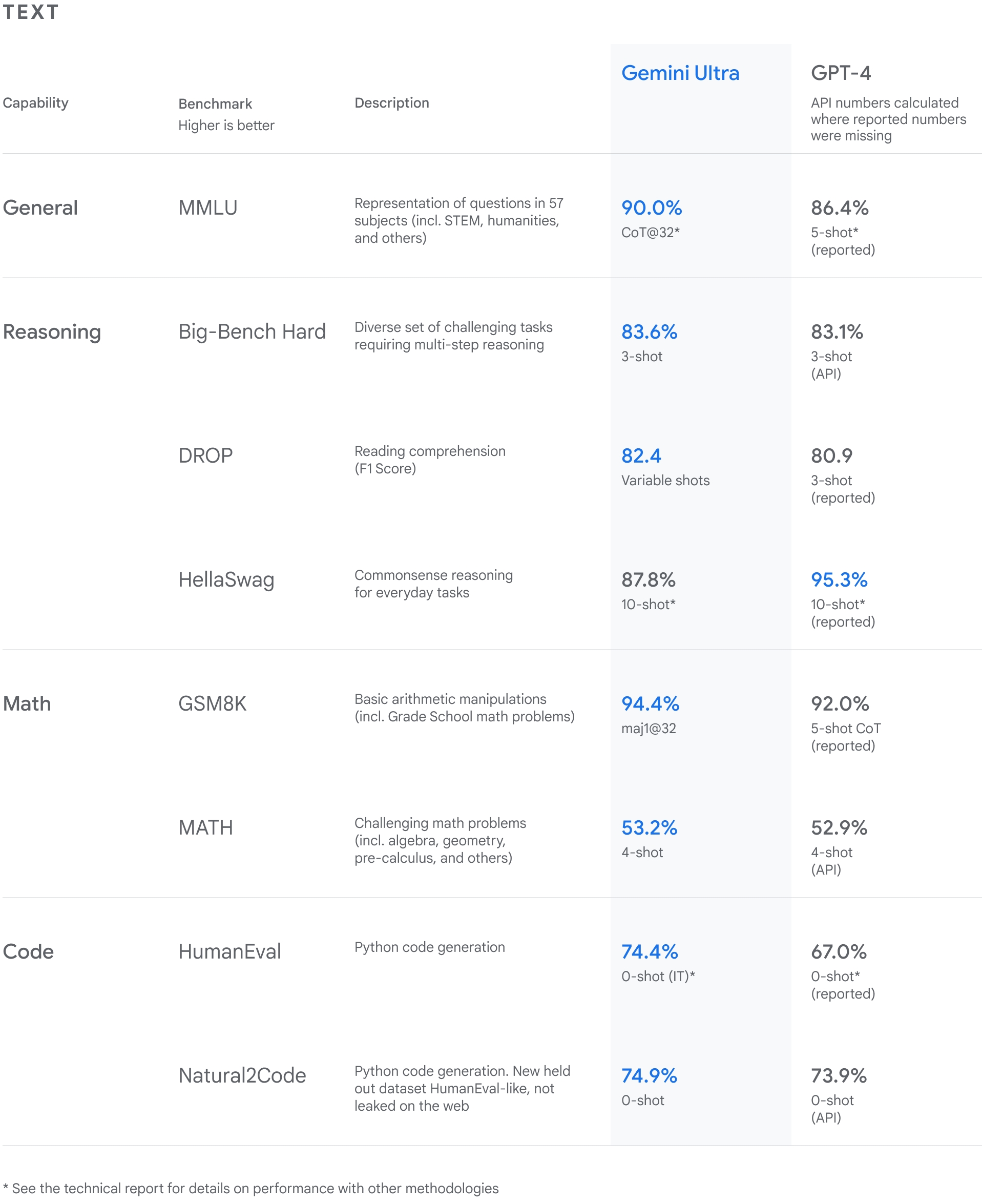
在性能上,Gemini 相當強悍。Google 放出了一系列測試結果,從自然圖像、音樂和影片理解到數學推理,在大型語言模型(LLM)研發中使用的 32 個廣泛使用的學術基準上,Gemini Ultra 的性能在 30 項上都超過了目前最先進的模型。
 △圖源:Google
△圖源:Google
更驚人的是,在 MMLU(大規模多任務語言理解)任務上,Gemini Ultra 的得分高達 90.0% ,是首個超越人類專家的模型。MMLU 是測試 AI 模型知識和問題解決能力的最主流測試,結合數學、物理、歷史、法律、醫學和倫理學等 57 個科目的問題。
寫程式,則是大模型衡量能力的重要維度。基於 Gemini,Google 本次還推出了更先進的寫程式系統 AlphaCode 2 ,它能理解、解釋並產生 Python、Java、C++ 和 Go 等寫程式語言的高質量代碼,還擅長解決一些超出寫程式範圍、涉及複雜數學和理論電腦科學的寫程式競賽問題。
比如,和上一代產品 AlphaCode 相比,AlphaCode 2 解決的問題數量幾乎是原來的兩倍,其表現優於 85% 的競賽參與者,AlphaCode 的這一比例接近 50% 。如果程式員通過為代碼示例定義某些屬性來與 AlphaCode 2 協作,它的性能還會更好。
「這是我們目前規模最大,性能最強的大模型,Gemini 可以像我們一樣,理解我們周圍的世界。」GoogleDeepMind CEO Demis Hassabis 表示。
 △圖源:Google
△圖源:Google
這次發布,Google 一口氣提供了 Gemini 的三個尺寸模型:Ultra、Pro 和 Nano,分別對其進行了優化:
Google 先將 Nano 搬到了自家的終端上。現在,Gemini Nano 已經可以跑在 GooglePixel 8 Pro 手機,Pixel 8 Pro 是為 Gemini Nano 設計的首款 Google 智慧型手機,不用聯網,就可以離線調用。
Pixel 8 Pro 先上了兩個自帶功能,一是把手機錄音內容自動歸納總結;二是在 WhatsApp 上聊天時,Google 鍵盤可以根據聊天內容,自動給出推薦回覆的文字。
Gemini Pro 就先被用在 Google 聊天機器 Bard 的升級上。Google 稱,這是 Bard 「自推出以來最大的升級」—— 在理解、總結、推理、編碼和規劃等方面的能力更強。Bard 集成 Gemini Pro 之後,已經在超過 170 個國家和地區提供英語服務。
為了展現升級後的 Bard 有多強,Google 甚至請了一個 教育 YouTuber Mark Rober,全程使用 Bard 作為輔助工具,從零開始畫圖紙,最後真的造出了一架巨大的紙飛機!
 △來源:Google
△來源:Google
Google 根據許多產業標準基準,對 Pro 版本進行了測試。結果顯示,在 8 個基準測試中的 6 個裡,Gemini Pro 的表現優於 GPT- 3.5 。
不過,性能最強的 Ultra 還要再等等。Google 表示,他們還要先給客戶、開發者、合作夥伴以及安全和責任專家進行早期實驗和回饋,預計在 2024 年初,Ultra 版本會先向開發者和企業客戶提供服務。
Google 還給大家畫了個餅。 2024 年初,Google 還將計劃推出 Bard Advanced,會由 Gemini Ultra 提供支持,能夠快速理解文本、圖像、音樂、影片等多模態輸入並採取行動。看起來,和現在火熱的 AI Agent(智能體)初級形態就非常類似了。
Gemini 的發布無疑是 AI 界又一個里程碑,這意味著 AI 大模型浪潮進入到一個全新階段。
比起大語言模型,多模態模型的運作模式,才是人類最自然的和世界交互的方式:用眼睛看到東西,用耳朵聽到聲音,再把這個東西的語義用聲音 / 文字輸出,再做出決策。
Gemini 的發布,只是掀起了多模態領域的一角。
多模態領域還在技術探索初期,技術路徑還未確定。比起大語言模型,多模態模型增加了音樂、影片、圖片這些數據,訓練難度也很大。
值得注意的是,影片內容已經是資訊時代的主流,據思科(Cicso, CSCO-US)的年度網路報告 —— 影片已經占據網路超過 80% 的流量。
這些數據的訓練還遠未到頭,意味著大模型的天花板上限還很高。如果 AI 領域的尺度定律(Scaling law)一直奏效,隨著訓練規模不斷擴大,我們還有許多可以期待的能力湧現。
「長期以來,我們一直希望從人們理解世界和與世界互動的方式中汲取靈感,建立新一代 AI 模型」Google DeepMind CEO 和聯合創辦人 Demis Hassabis 表示,「今天,當我們推出 Gemini 時,我們離這一願景又近了一步。」
站在現在這個時間節點,距離 ChatGPT 震撼世界的發布剛好過去一年。這一年裡,全世界的 AI 公司夜以繼日地奮鬥,或多或少都為了回答一個問題:到底還能有誰,可以超越 OpenAI?
Meta 旗下的 Llama 試圖以開源路線,集眾人之力;而在和 OpenAI 一樣的閉源路線上,Google 是當仁不讓的最強大對手。
Google 是這輪大模型技術突破的先驅,GPT 模型的核心 Transformer 架構正是出自 Google 之手。但在今年的 AI 大戰中,Google 一直被稱為 「起個大早趕個晚集」。
和 OpenAI 的對線中,Google 的回應總慢一拍,對標 ChatGPT 的聊天機器人 Bard 匆忙上線,先前並沒有獲得很大的市場聲量,客戶拓展也很緩慢。
痛定思痛的 Google,將 AI 研究原來的 PaLM 2 ,全線切換到 Gemini,並開始調遣精兵強將反擊。2023 年 8 月,Google 將 Google 大腦(Google Brain)和 DeepMind 兩路人馬合併,數百名 AI 精兵開始瘋狂沖刺,才有了 Gemini 的誕生。
從如今公布的參數和使用效果來看,Google 的 「AI 家底」 還是不菲。Gemini 發布後,Google 算是可以揚眉吐氣了。
而 Gemini 發布的當下,全球的 AI 大模型競賽進入了新一輪競爭,戰局又變得面目模糊。
雖然 OpenAI 占有先機,通過 ChatGPT 獲得了大量訓練數據回饋,Google 也依然有著自己的優勢。The Information 先前報導,Gemini 至少在一個方面比 GPT- 4 強:除了來自網路的公共資訊之外,Gemini 還利用了來自旗下產品的大量 Google 專有數據。因此,在理解用戶特定查詢的意圖時更準確,而且錯誤答案(即幻覺)也似乎更少。
不過,即使 Gemini 放出來的效果驚人,但現在的 Google 還不是特別有底氣,Gemini 的實際應用效果也有待驗證。
據 CNBC,Gemini 發布前,Google 還是猶豫不定,曾多次延遲發布日期,如今又因為市場壓力突然決定發布。Google 的高層們在媒體溝通會上表示,Gemini Pro 的性能優於 OpenAI 的 GPT- 3.5 ,但回避了有關 Gemini 與 GPT- 4 相比的問題。
TechCrunch 更是直言:「Gemini 並不是我們所期待的大模型」,表示 Google 有點吹噓過度。雖然 Gemini 在 30 項測試中都獲得了最好成績,但實際上,很多項都是略略高於 GPT- 4 和 GPT- 4 with Vision 等模型而已。
作為大公司,Google 要想繼續追趕,困難還有很多。The Information 表示,Google 正在努力解決在非英語查詢等任務上的困難,並且內部對 Gemini 的提前發布意見不一,對 Gemini 的獲利策略也沒定下來,商業化難辦。
而在 OpenAI 那邊,因為董事會解雇 CEO 又回歸的戲碼,公司尚在艱難的 「災後重建」 中,剛推出的 GPT 高級版無限期暫停,GPT 商店更是延後到了明年。先前,OpenAI 還放棄過一個重要大模型項目 Arrakis 的訓練,側面反映了還有不少技術難題等待解決。
如今,一些新勢力也悄然冒頭。比如馬斯克的 xAI 就進展飛快,正在計劃融資 10 億美元,接下來一周內,還會向訂閱會員上線使用權限。
在歐洲,也出現了立志再造 OpenAI、「開源一切」 的 Kyutai,以及 Mistral AI 等公司,後者也同樣是由來自 Google、Meta、Hugging Face,曾經深度參與過 Llama 研發的尖端人才參與創立。
這場 AI 新勢力的競賽,真是越來越精彩了。
《36氪》授權轉載
【延伸閱讀】
超好賺!
每天都有任務能拿獎勵,快點擊查看!

















