1

產業
我在上一篇文章裡講到了輝達 (Nvidia) 在 AI 領域的競爭優勢,從收到的評論來看,很多人並沒有理解在機器學習中訓練和推理的區別,從而衍生出了一系列錯誤的對比和觀點。
機器學習中需要用到高計算性能的場景有兩種,一種是訓練,通過反覆計算來調整神經網路架構內的參數;另一種是推理,用已經確定的參數批量化解決預定任務。
比如下面這張圖的例子:用機器學習來識別圖片上的物體是否是花。要做到這點,首先得選擇一個模型,假設我們選擇的模型是一個四層的神經網路:第一層是輸入層,中間的兩層叫隱藏層 (hidden layer) ,最後一層是輸出層。每一層都有三個結點,每個結點的連線上都有一個對應的參數。用機器來進行圖象識別過程就是把圖片的像素點訊息從輸入層傳入,經過和每層參數之間的計算,最後到達輸出層,如果輸出的數字是 1 表示圖片是一朵花,輸出是 0 表示不是一朵花。
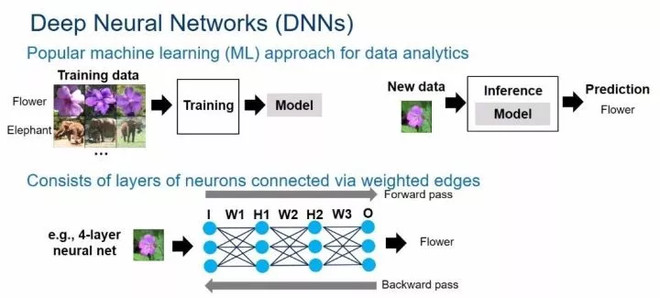
要想實現這個應用,第一步就得訓練好模型。所謂訓練,目的就是尋找到一組參數值使得預測的錯誤率最小,過程大概如下:
要注意的是,這裡只是一個非常簡單的網路,訓練集也很小。在真實的應用場景中,模型會更複雜,需要訓練的參數可能會高達上萬個,計算量的需求會指數級成長。
但是一旦模型訓練好,參數也就固定下來了。再有新的圖片進來,按照定義好的模型和參數進行計算,根據計算的結果就能判斷圖片是否是一朵花了。這個過程就是推理。推理對計算能力的要求相對於訓練就沒那麼高了。
推理可以在雲端來做也可以在設備上來做。比如你用手機拍了一張照片要識別是否是花,應用程式可以把照片發送回數據中心的服務器來進行推理計算,再把結果返回到手機。也可以直接把模型放到應用程式內,使用手機上的晶片進行計算從而得出結果。
方案 1 的弊端是得依賴於網路,而且因為需要來回傳輸數據而有延遲;方案 2 的好處是不需要網路,但是對設備的計算能力有一定的要求。
下面這張圖就是展示了不同廠家,不同種類晶片在機器學習計算中所處的場景。橫軸從左到右表示性能和功能,越靠右越強大;縱軸從上至下分別是訓練;推理,在設備端計算或者設備雲端混合計算 (edge/hybrid); 推理,在雲端數據中心一側計算。
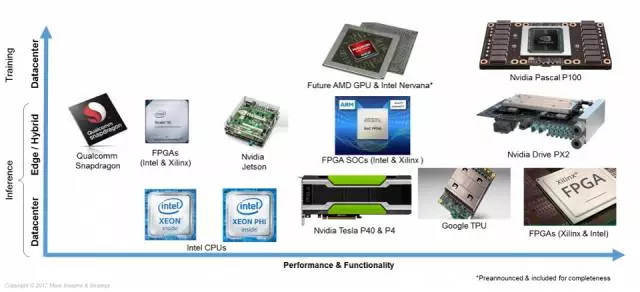
上圖涉及到了晶片種類有這麼幾種:GPU,CPU,FPGA 和 ASIC。
GPU (以前是 Graphics Processing Unit 圖形計算單元,如今已經是 General Processing Unit 通用計算單元) 具有高的計算能力、高級開發環境、不影響機器學習演算法切換的優點,雖然同等計算能力下能耗最高,但仍然在演算法開發和機器學習訓練場景中佔據絶對的市場地位。
CPU 更適合的是通用邏輯的計算,而不是大規模的並發運算。所以 CPU 不會被用來做訓練,目前在推理計算環節被廣泛採用。但即使是在推理環節,CPU 的性能也遠不如根據機器學習算法特點專門設計的晶片。
FPGA (Field–Programmable Gate Array,現場可程式邏輯門陣列) 是一種半成型的硬體,需要通過特定的編程語言定義其中的單元配置和連結架構才能進行計算,相當於也具有很高的通用性,功耗也較低,但開發成本很高、不便於隨時修改,訓練場景下的性能不如 GPU。
ASIC (Application Specific Integrated Circuits,特殊應用積體電路) 是根據確定的演算法設計製造的專用電路,看起來就是一塊普通的晶片。由於是專用電路,可以高效低能耗地完成設計任務,但是由於是專用設計的,所以只能執行本來設計的任務,在做出來以後想要改變演算法是不可能的。
Google 的 TPU (Tensor Processing Unit 張量處理單元) 就是一種介於 ASIC 和 FPGA 之間的晶片,只有部分的可定製性,目的是對確定演算法的高效執行。
有了上面的基礎知識,我們再來看一下整個的競爭格局。
首先在機器學習的算法研究開發以及訓練領域,GPU 佔據了絶對的領導地位,而這裡的 GPU 基本可以認為就是輝達的 GPU,我沒有確切的數據但保守估計輝達在訓練領域 GPU 的市場份額至少占到了 80%,可以說處在了一個絶對壟斷的地位。
這塊最大的挑戰是來自於 Google 的 TPU。 Google 已經宣稱其 TPU 既可以用在訓練環節,也可以做推理運算。
從 TPU 的設計來看,是一種介於 ASIC 和 FPGA 的一種晶片,可以認為是專門針對 Google 自家的 Tensorflow 來設計的。 Google 沒有披露太多的細節,但按道理來說用 TPU 跑別的機器學習框架應該性能不行,用 TPU 來開發新的算法肯定也是不適合的。但考慮到 Tensorflow 越來越流行,TPU適用的群體和場景也不可小覷。但是 Google 還沒有對外銷售 TPU 的計劃,而是把 TPU 作為 Google Cloud 差異化競爭的重要一環。
結論就是 TPU 對輝達 GPU 的具體影響還要再持續觀察,不過很重要的一點就是整個市場還是在高速成長,TPU 爭搶的也是一個在不斷做大的蛋糕。
上面提到推理的場景有兩種:在數據中心進行計算;或者在設備端。但未來的應用應該還是設備端占主流,比如無人駕駛汽車需要實時的去識別路上的物體,這個是不可能把數據回傳到數據中心去做判斷的。
從市場的角度來看,有數據指出深度學習的訓練市場是 110 億美元,而推理市場的規模是 150 億美元,比訓練領域更大,而且還處在市場的開發早期,主要是由 CPU 來完成。但各個廠家也都在推出各自的方案,比如基於 FPGA 的方案,或者是專用的 ASIC,蘋果(Apple, AAPL-US)就是自己設計了自己的人工智慧晶片。
需要注意的是,輝達在推理領域並沒有像訓練領域這樣的優勢,市場也對此沒有太大的預期。昨天花旗的一份研報中,分析師就說:Nvidia is “widely perceived as an underdog (處於劣勢,下風) in inferencing given architecture optionality around the use of CPU, FPGA, and TPU.”
這裡主要的原因是 GPU 的功耗太大,不太適合用在終端設備上,而且輝達也沒有在推理領域構建出像 CUDA 這樣完善的軟體生態系統。但是,輝達在推理領域的潛力還很大:
總之,雖然輝達在推理領域將面臨激烈的競爭,GPU 本身在性能上也不具有絶對的優勢,市場對此的預期也很低,但輝達在這塊市場未來的潛力不可忽視。
我個人的體會是,作為非深度學習專業的投資者,一定要搞清楚上面說到的訓練和推理兩個領域的差別,這樣才能正確的解讀新聞。
比如,之前看新聞說某公司研發出一款專門針對人工智慧的晶片,比 CPU、GPU 都要快,然後還評論說,在人工智慧時代 CPU、GPU 都過時了,我們這個 NPU 才是未來。其實仔細一看,不管你叫 NPU 還是 xPU 的,本質上就是針對推理環節設計的 ASIC 晶片,這個對輝達在訓練領域的競爭優勢沒有任何的影響。
還有最近的一則新聞,傳特斯拉(Tesla, TSLA-US) (Tesla) 放棄輝達和 AMD 合作開發無人駕駛晶片。首先,這個無人駕駛晶片名字看著高大上,實際上就是用來完成推理計算的晶片。上面也提到,這個並不是輝達的優勢領域,輝達有特斯拉這樣的客戶固然是一件好事,但丟掉了也不影響大局,輝達也有豐田等其它的汽車行業的合作夥伴,而且這件事對輝達的核心競爭力 (訓練領域的優勢) 也沒有任何的動搖。
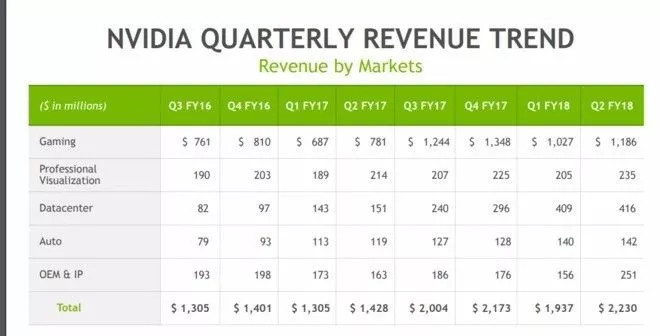
對於輝達的總體業績,影響因素並不僅僅只有人工智慧、深度學習這一塊。從下面的業務劃分來看,datacenter+auto 這兩塊業務只占整體業務的 25%,但提升速度還是很驚人的,2016 財年 Q3 季度只占 12%。 值得注意的是,收入占比接近 50% 的遊戲業務今年還是成長不錯的。
一方面原因是幾年任天堂 switch 的熱銷,另外雖然這幾年手遊很火,桌面遊戲依然擁有廣大的玩家,今年遊戲大賣應該對遊戲顯示卡的銷售有很大的拉動作用。
現在分析師對輝達給出的最高目標價是 250 元,我沒有看分析報告全文,但我猜測大概的模型是這樣的:今年的每股盈利按現在的趨勢會到 3.6 元左右,然後接下來的三年每年複合成長 40%,到 2020 年每股盈利會到 10 元,業績增速會放緩到 20%-30% 區間,按 25 倍 PE 就是 250 元。
客觀的說,這個預測還是非常樂觀的,而且按這個預測到 2020 年的合理估值是 250 元,而現在的股價已經是 200 多了,潛在的上升空間已經不大,之前一年漲 3 倍的盛況肯定也不會再有。但從另外一個角度,在 AI 晶片這塊,輝達已經佔據了相當好的一個位置,如果 AI 是未來十年的大趨勢,輝達持續成長的時間跨度或許會很長。
未來永遠都有不確定性,所有的判斷都需要動態的修正,但是手中有一副地圖至少能讓你知道觀察的對象什麼時候偏離了正確的軌道。
《雪球》授權轉載
【延伸閱讀】
超好賺!
每天都有任務能拿獎勵,快點擊查看!