1

產業
前篇引導:數據分析專題(五):類神經網路的復興:深度學習簡史
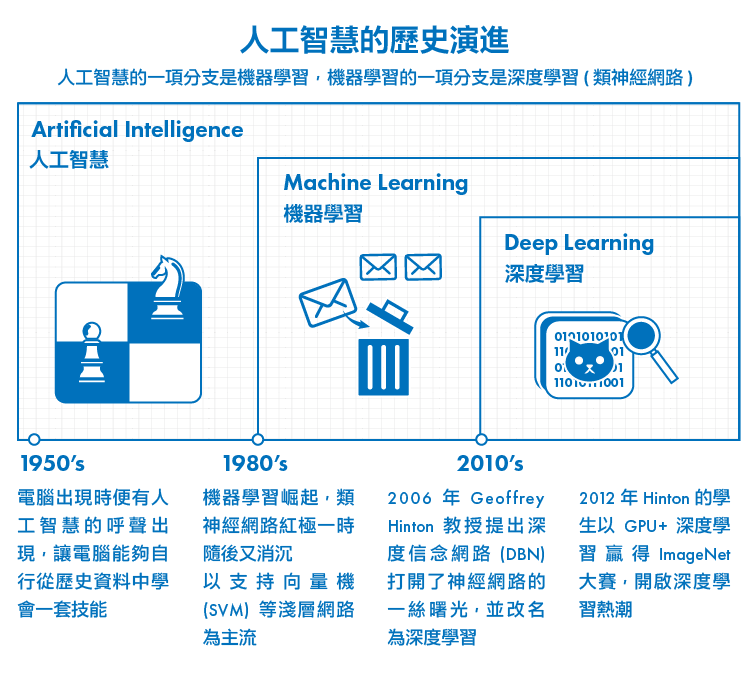
由於多層神經網路的計算量龐大、訓練時間過長,常常跑一次模型就噴掉數週、甚至數月的時間,2006年該時也僅是讓學界知道:「深度神經網路這項技術是有可能實現的」而已,並沒有真正火紅起來。
真正的轉捩點,還是要到2012年——那年10月,機器學習界發生了一件大事。
還記得我們在【人工智慧的黃金年代:機器學習】一文中提過的ImageNet嗎?美國普林斯頓大學李飛飛與李凱教授在2007年合作開啟了一個名為「ImageNet」的專案,他們下載了數以百萬計的照片,供機器從圖像資料中進行學習。每年史丹佛大學都會舉辦ImageNet圖像識別競賽,讓各家企業或機構測試系統的效能極限,堪稱機器學習界一大盛事。
以往無論是淺層、還是深度學習的機器學習模型,都是採用CPU進行運算。2012年10月, Hinton的兩個學生使用輝達(NVIDIA, NVDA-US)出產的GPU、加上深度學習模型 (他們採用了專做圖像識別的捲積式神經網路CNN),一舉拿下ImageNet的冠軍,正確率更超過第二名將近10%。有興趣的讀者可以參考由Hinton撰寫的這篇論文《Imagenet classification with deep convolutional neural networks》,內文詳細介紹了相關模型與比賽結果。
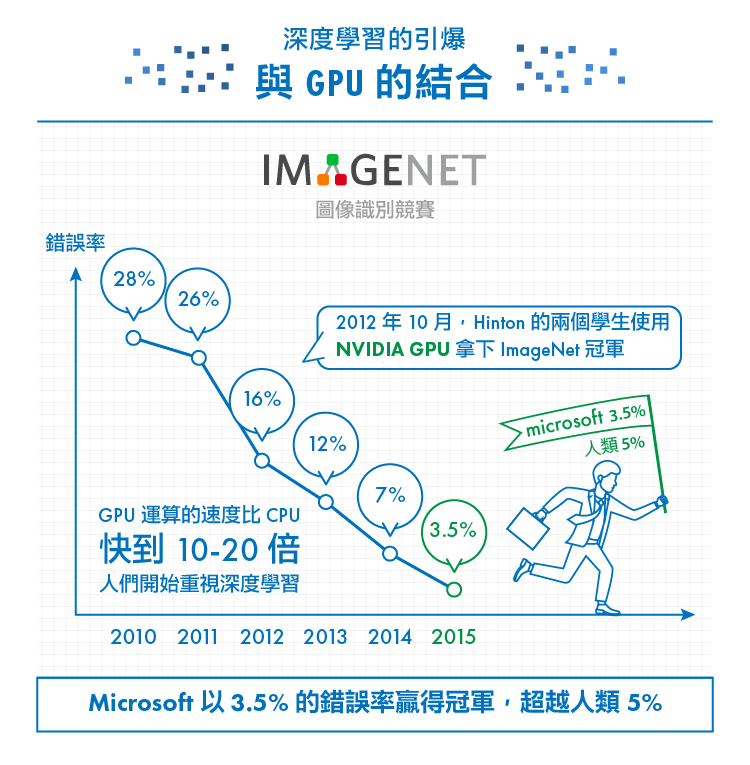
看到此情此景,大家都瘋了,NVIDIA也瘋了。沒想到採用GPU運算的深度學習能有如此殺傷力強大的效果,運算速度是CPU的70倍以上,終於讓深度學習真正火爆起來。2012年之後的ImageNet競賽,大家都紛紛採用GPU做運算;2015年,Microsoft更是以3.5%的錯誤率贏得冠軍,超越人類肉眼5%錯誤率的辨識能力。
為什麼GPU運算會比CPU更強呢?GPU不是用來處理圖形運算的嗎?由於圖形運算需要大量的向量和矩陣運算,這正是平行架構的GPU最擅長的事情,而深度學習正是使用大量的向量和矩陣進行運算;CPU執行矩陣運算的速度則遠遠不及GPU。
事實上,CPU是用來進行更通用的運算,需要協調硬軟體資源;而GPU計算是用於增大計算的吞吐量。CPU需要很快的將資料一個個的依次處理完畢,降低延遲時間;而GPU到記憶體的抓資料回來運算的速度比CPU慢很多,所以GPU計算都是希望一下子有很多數據可以計算,然後一口氣將這些數據計算光。
深度學習矩陣運算+大數據平行運算=首選GPU
註:流言終結者(Mythbuster)的兩位主持人Adam Savage和Jamie Hynema曾以特效裝置示範CPU和GPU平行運算的效能差異(還被NVIDIA官方頻道貼出來lol),推薦讀者可以看一看,好笑又好懂。
NVIDIA一直想從設計圖形處理器的傳統硬體公司轉型、成為大規模運算伺服器和整合軟體公司;因而在深度學習爆紅之前,早已推出了GPGPU(通用圖形處理器)。
我們之所以能用CPU做運算,是因為CPU有編譯器(Compiler)這樣的設計,能讓工程師寫完程式後、經過編譯器的轉譯、成為CPU看得懂的機械碼。然而一般GPU並沒有類似的設計,因此工程師難以直接寫程式讓GPU來運算
CUDA——NVIDIA成為深度學習運算必用硬體的關鍵。
2006到2007年間,NVIDIA發表了一項全新的運算架構,稱為CUDA;這也是NVIDIA正式給GPGPU的名稱。使用者可以撰寫C語言、再透過CUDA底層架構轉譯成GPU看得懂的語言。這也是自GPU可以拿來做大規模運算的概念推出之後,首次可以讓人使用C語言來運用GPU蘊藏已久的強大運算能力,故NVIDIA從GeForce 8系列之後的顯示卡全開始支援CUDA技術。
GPGPU的興起,大概就是CUDA帶起來的;而CUDA的成功,更直接導致了深度學習的運算全部都使用NVIDIA家的GPU。這種驚人的影響力,不論是深度學習、機器學習、自動車、虛擬實境(VR)、電競遊戲,每一項都跟NVIDIA習習相關。Tesla創辦人Elon Musk更是親自寫Email,向NVIDIA執行長黃仁勳表達希望成為第一個拿到最新AI GPU的人。
今年八月,NVIDIA在其每年舉辦的GTC大會上(GPU Technology Conference,俗稱老黃的傳教大會),執行長黃仁勳強調NVIDIA在人工智慧領域上的深耕、能提供最完整的軟硬體解決方案。整場大會以深度學習為重要主角,同時宣佈推出全世界第一個專門用來運算深度學習的超級電腦——DGX-1伺服器,售價129,000美金。
搭上人工智慧熱潮,NVIDIA從12月開始連續9個交易日創歷史收盤新高、今年迄今漲幅高達255.95%。MarketWatch報導,NVIDIA是今年迄今標準普爾500指數表現最好的成分股。
如今深度學習技術對各大產業領域都將產生深遠的影響,堪稱第四次工業革命。從天氣預測、醫療影像辨識、金融股市預測、電信商客戶流失率預測、網路異常入侵偵測、智慧交通…無不採用深度學習技術。

基於深度學習方法,Facebook的DeepFace專案的人臉識別技術的識別率已經達到了97.25%,接近人類的97.5%的識別率,幾乎可媲美人類。
Google現在則有超過1000個深度學習產品,包括地圖、GMAIL、自動翻譯、自動車、Android等。2013年7月,Google收購了DNNresearch公司,其背後創辦人正是大名鼎鼎的深度學習之父Hinton教授;2014年1月,Google以逾6億美元價碼收購英國人工智慧公司DeepMind。
今年(2016)三月,由DeepMind團隊所打造的AlphaGo圍棋系統在擊敗的南韓圍棋好手李世石之後聲名大噪;隨後Google也利用DeepMind的深度學習技術,把各資料中心的用電效率提高15%、成功讓其龐大的資料中心冷卻用電量減少了40%。
深度學習能推廣應用的產業範疇非常的多,各家科技公司更是摩拳霍霍、無不想搶進最新發展。在人工智慧領域中,目前領先的四大巨頭分別為Google、Microsoft、Facebook與百度(Baidu, BIDU-US);尤其在語音識別和圖像辨識上,每個月都可以看到這四家公司公布新的技術發展。每分每秒,AI巨頭們都在使用深度學習改變你我的生活。
當然你可能會想:說了這麼多、什麼機器學習、深度學習,還不是只有大公司玩得起。
2015年,約每22天就有一個深度學習的工具集(toolkit)被發布出來。深度學習正從高冷的數學模型、逐漸邁向黑盒子的過程。這是什麼意思呢?
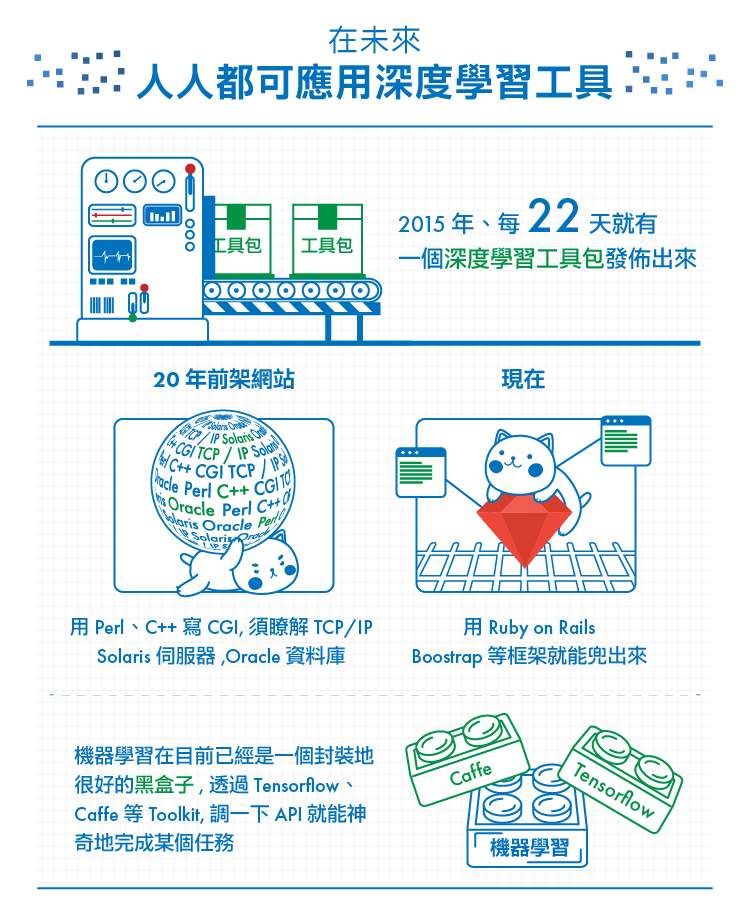
以網頁開發來比喻——20年前架網站,工程師得用Perl、C++寫CGI、瞭解TCP/IP標準、Solaris伺服器、Oracle資料庫;簡單來說,寫網頁是一個具備高度Domain-knowhow的活兒。然而現在不需要瞭解底層架構,用Ruby on Rails、Bootstrap等框架,輕輕鬆鬆就能兜一個網頁出來。市面上隨意可見「1天教你學會架站」之類的書籍。
同樣地,機器學習和深度學習模型在目前已經是一個封裝地很好的黑盒子;使用者只要下載Package、透過Tensorflow、Caffe等開源平台Toolkit、調一下 API,把資料丟進去,就能神奇地完成某個任務。即使不瞭解背後的數學模型,仍然可以很輕鬆地使用深度學習做數據分析。
最近在日本就有個有趣的案例——小池誠原本在車廠當工程師,一年前辭去工作回到老家幫父母經營小黃瓜農場。農場並不大,然而小黃瓜分類的工作卻讓他吃了不少苦頭。
小池誠不懂深度學習的數學模型,但透過TensorFlow平台、他成功利用深度學習來為自家的小黃瓜進行圖像辨識和自動化分類。
你能想像在你家的農場使用深度學習技術嗎?或許就像使用Excel做數據分析一般,在未來,人人都能輕易地使用深度學習模型來跑海量數據。
在本篇系列的最後,讓我們來討論一下這個恆久不變的問題。
問題1. 人工智慧有可能毀滅人類?
在許多科幻小說中,屢見不鮮人工智慧程式透過自我學習,最終逐漸統治世界的故事。既然機器學習能自行從歷史資料中學會技能,目前人工智慧的技術發展有可能導致這種情況發生嗎?會導致強人工智慧(Strong A.I.)的出現嗎?
目前人工智慧的自我學習還是限定在人們指定的方式、只能學習解決特定的問題,比如說AlphaGo不能直接去下象棋,仍然不是通用的智慧、或能理解「下棋」的意義,對於AlphaGo來說只是跑完一個運算模型。
還記得我們提過,機器要能從海量資料中挖掘出規律,必須經過資料清整 (Data Cleaning)的過程嗎?資料科學家得為系統輸入規整化的訓練資料,格式要求相當嚴格。這也意味著即使把人工智慧程式連到網上,它也不能直接對於網路上格式不一的「骯髒」資料進行學習。
問題2. 機器學習和深度學習是不是沒有達不到的事?
這個問法或許可以改成:什麼是機器學習能解的問題、什麼是機器學習不能解的問題?
機器學習是一門結合了機率學與統計學的學科,早期做機器學習的學者幾乎都是統計學家,直到後來有電腦科學背景的研究人員進來、結合統計和資工兩方的Domain-Knowledge,成為一個叫機器學習的新門派。因此無論是線性回歸、Sigmoid函數邏輯回歸、SVM、RBM…等模型,事實上都是統計學模型。
既然如此,統計和機器學習有什麼差別呢?他們想要解決的問題是不一樣的——傳統統計更在乎解釋能力(explanation power),機器學習則在乎預測能力(prediction power)。目標不一樣,發展出的建模方法就不一樣。
機器學習就像一個黑盒子,可能跑出了非常精準的預測結果、卻不明白機器是透過什麼樣的過程、用什麼方法預測出這個答案的。
對於統計學家而言,關心的問題則是:我的模型到底能不能解釋整個母體的現象;如果預測錯誤率更低、但沒辦法解釋原因,就會放棄該模型。若目標在於解釋的話,不用做出一個「預測準到不行」的模型,但估計式要穩健(robust)。
你可能會想:預測準確不是比較重要嗎?為什麼要在乎解釋能力呢?在發展科學理論的時候,若不解釋、就算預測的再準,我們還是不能理解一個現象為什麼會發生。比如說,我們可以透過機器學習模型很準確地預測點擊率,但我們仍不知道是什麼因素影響CTR,如此一來就很難去改良產品設計,就算將點擊率預測地很準也沒用。
因此在許多深度學習研究論文中,可以發現其理論都不太「漂亮」——理論不甚完備、但實務上的預測結果跑的不錯。
既然說機器學習需要過去的資料來學會技能、並透過新進資料逐步優化,因而對於深度學習模型來說,十萬筆資料都是小數字。但若是沒有歷史資料呢….?
比如我們可以從一個消費者過去的購買資料中,精準預測到他會買產品A,然而在公司想販售一款新產品B時,由於無法解釋他為什麼會買產品A,也沒有產品B的歷史資料、因此無法預測該消費者會不會買這款新產品。
況且對一般人而言,很難輕易達到數十萬筆以上的資料量,如此使用Excel進行一般統計運算即可。進一步說,多數台灣企業的資料庫老舊、許久沒有維護更新,說要能拿出夠「乾淨」的海量數據來進行分析,也是頗為困難的事情。
針對上述問題,有時候用統計、另一種時候用機器學習模型。實務上,資料科學家會依據問題的類型和自身經驗、考量後選擇適當的工具。
大家對於人工智慧、機器學習和深度學習有了更進一步的認識了嗎?從人工智慧、機器學習到深度學習,人工智慧領域的發展日新月異;深度學習的浪潮方引爆,未來世界的運作方式將會如何受變化呢?就讓我們拭目以待吧。
感謝您收看本利列的數據分析專題,我們下次再見!
【延伸閱讀】
超好賺!
每天都有任務能拿獎勵,快點擊查看!